Week 11
2,522 words · 13 min read
Summary
3/23 - 3/29
Meetings
- 3/24 3:30-4:30PM Tuesday, 1-on-1-on-1 with Prof. Adams and Grace Lingley
Accomplishments
- Cloud Assignment 3 Part 2
Cloud Assignment 3 Part 2
Cloud Assignment 3 was completed this week. The final tasks of the cloud assignment are:
Part 1: N-Tier Architecture
- Adding a reverse proxy
- Introducing Docker Compose
- Pushing to a container repository (+10)
- Automating deployments with Ansible (+10)
- Introducing Terraform (+10)
- Importing existing infrastructure (-30/+30)
- Re-deploying bird.ai (+10)
- Choosing a domain name (+10)
Part 2: Squirrel-due University
- Enabling HTTPS (+10)
- Squirrel detection (+10)
- Stripping EXIF data (+20)
- Gossip Squirrel (+10)
I’ve kept a running list of obstacles and architectural decisions for Part 2.
The first task introduced HTTPS and SSL certifications. My initial idea was to set up Let’s Encrypt’s Certbot running on the proxy, and have the students configure Nginx to read the certificates it generates. Certbot is subject to rate limit of 50/week for a single domain (our cs351.cloud), however we have 70 students in the class. It’s unfortunate, it’s one of the universal and accessible methods for implement TLS encryption. Instead, I’ve had them put a Cloudfront server in front of the proxy to perform TLS termination, although traffic between the CDN and the EC2 instance remains unencrypted. AWS Certificate Manager handles certificates for Cloudfront and has high rate limits (2,500/year per account).
Future assignments incorporating HTTPS should give more thought to provisioning certificates. We would have to run a central server that manages DNS and coordinates with Let’s Encrypt using DNS-01. Students would interact with it through an API/UI to manage assignment DNS. The student experience could be enhanced by providing Amazon Machine Images (AMI) that automate this.
Deploying production applications is tricky, and not always easy to encapsulate in an assignment. Now, Cloudfront+ACM is quite robust, I use it for most of my personal projects, so this assignment can stay the same for future sections. Whether it transfers neatly to other clouds, I’m not as sure.
Claude has gotten really good. Context size increased from 250,000 tokens to 1,000,000 tokens while I was developing this assignment, improving its ability to complete long tasks. I’ve also noticed its ability to explain complex topics as improved, and it has developed a propensity for creating charts and examples as part of these explanations. My crazy idea seems to be more possible every day, the key is understanding what type of scaffold (aka “agent harness”) is needed to deliver that type of experience.
Had to increase the YOLO model size from nano to large (that’s a size increase from 11MB to 75MB), the nano wouldn’t detect squirrels. Curiously, the xlarge model was worse at detecting squirrels and birds than the large. It has to do with the open text embeddings we use to power this NLP-based image detection, smaller models can be trained to better detect these open-ended embeddings than large models. The increase in model size increased response times 10x, and memory use has increased quite a bit too. One time during inference the website returned a 503, the thread had been killed due to Out-Of-Memory, the t4g.small is not the right fit for ML applications. I rode my bike around Purdue on Sunday taking pictures of squirrels and birds, so the gossip protocol is seeded with images and locations. You can visit my application at https://ccouetil.ca3.cs351.cloud. The YOLO model is really bad at detecting birds and squirrels!
Here’s a screenshot of the new feature students implement in Part 2.
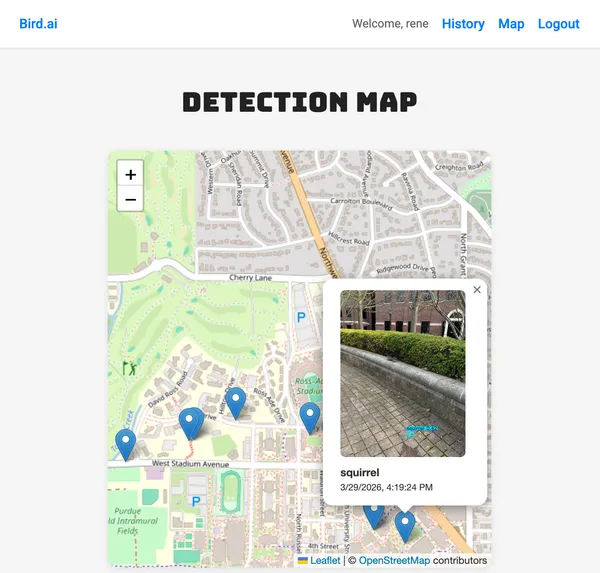
Keeping this assignment in the free tier was difficult. ECR Public vs Private size limits and rate limits caused issues. TLS Certificate rate limits other issues. Disk space limits on EC2 instances another restraint. Overall, I estimated the cost of this assignment to be around $35 if a student leaves their infrastructure running for 10 days outside of the free tier. The resources used in the assignment are:
- EC2 instances (c7i-flex.large, t3.small, t4g.small)
- RDS database (db.t3.micro, PostgreSQL)
- EBS volumes (18 GB gp2 total)
- RDS storage (20 GB gp2)
- S3 bucket for Terraform state file
- Two Cloudfront distributions
- ECR public container repository
The EXIF data stripping didn’t go quite as expected, iOS aggressively strips location data from images, even if you explicitly allow location access in a bunch of settings. I think the website would have to be an smartphone application in order to make the location stripping work effectively. It wasn’t feasible to do GeoIP for this assignment. To keep the EXIF intact for images I took with my iPhone, I had to enable location services and export the photos out of the Photos app onto my Desktop folder before uploading those files to the web application. I think this section should be tweaked for future versions of this assignment.
I developed an instructional API server to support the DNS and gossip features. The instructional API server supports both:
the students:
/dns- manage DNS records/dns/acme-validation- submit TXT record for DNS-01
and the autograder:
/dns/lookup?account_id=*- return DNS records for student AWS account.
The API server uses an open-source Python library called FastAPI, and runs on a separate EC2 instance from the instructional site. I can’t really justify why I made this API separate from the instructional site, I just preferred the idea of any supporting resources for a particular cloud assignment to be separate from the instructional site itself, which is meant to support all cloud assignments. However, this is another burden of deployment and maintenance when this cloud assignment is run again in future sections of the course.
Cloud Assignment 4
RCAC has gotten back to me, apparently I missed their initial message during Spring Break. I will try to get a meeting with them next week, and see what they can offer in terms of support for this assignment.
Let me consider what the two parts of CA4 will be.
Part 1: Migrating bird.ai to Kubernetes
- Deploy the monolith so its on AWS EC2 instance.
- Containerize the ML model as a separate REST API service.
- Deploy the ML model service onto Kubernetes.
- Update the monolith to call the new ML model service.
- Deploy a new instance of the monolith onto Kubernetes (reverse proxy will load balance between the old monolith and new monolith. But how to handle DB? DB migration may have to be a separate step).
- Now, kill the old EC2 instance. Whatever load balancer we are using should detect dropped requests and route everything to new monolith.
Part 2: Vibe code something and deploy to Kubernetes
- will provide integration details for how to use a DB on the cluster.
- will provide step-by-step to deploy different supporting services on the cluster.
- PostgreSQL, ClickHouse,
- will have to provide instructions for setting up DNS for their project.
- need to define the evaluation criteria for the assignment, so students
deliver something we can confidently assign 50 points to.
- must be accessible over the internet
- must have a user login
- must be HTTPS enabled.
- if they need a domain name, talk to us.
- students will have to submit a 5 minute video demo, and a document explaining their motivation, the problem solved, and how to use it.
I believe at this point in the semester, if the students ran the architecture from all assignments for the full 10 days of each release period, we would be about 2/3rds of the way through the $100 AWS Free Tier.
I will research AWS EKS (Elastic Kubernetes Service) this week.
Cloud Assignment 5 ideas
This will not happen this class section, but in my conception CA5 would be implementing a function-as-a-service on Kubernetes.
Learning outcomes:
- become familiar with Kubernetes networking
- become familiar with how Kubernetes schedules one-off container runs (to service the HTTP request). And then evolve that to persist the container for a few minutes (cold-start vs hot-start).
- how does Kubernetes manage containers?
- scheduling, caching, etc.
- understand how FaaS are implemented, and use that perspective to judge architecture trade-offs in professional roles.
Task list:
- implement container runtime API
- translates HTTP request into a set of objects the container receives from the control plane.
- accepts a TCP socket and a list of arguments that corresponding to HTTP request parameters (headers, query parameters, path, body, etc.)
- Set up control plane API that an API client interacts with.
- hosted on kubernetes cluster
- Set up API client that interacts with the API server.
- point it at a built container locally and specify a name
- implement the image storage
- open-source container registry.
- implement the container run
- how do you run the container on demand?
- implement the networking
- connecting an IP address to the container
- implement DNS
- assign name to IP address of a container
- implement hot starts for containers
- implement container block de-duplication for images (this is likely hard)
- implement runtime limits, memory limits, cpu limits, firewall rules, etc.
- code your own function, deploy it, submit.
Advanced Cloud Assignments
Cloud assignments could be adaped for the graduate course. Instead of detailed starter code, the assignment would contain guidelines and they would have to code it all themselves, using autograder feedback to guide their implementation to the correct solution. Basically, they vibe code their way to the solution with no starter code, just the goals, principles, and deliverables expressed in prose, diagrams, rules, and tables.
Riffing on IEEE Spectrum Article
The article provoked some thought. What does the future of software look like? Or computational products more broadly?
I love tennis. Let’s train a video model to perform line calls and score tracking for a tennis match. Use a simulated world model of a tennis match to RLHF the video model.
This paper built a tennis game simulation to train a physical robot to play tennis, and successfully. They open sourced the code.
https://zzk273.github.io/LATENT/static/scripts/Humanoid_Tennis.pdf
The training pipeline from the open-source repository is:
- Motion capture 5 amateur tennis players
- Convert human poses to robot joint angles using LocoMuJoCo
- Train a movement policy using reinforcement learning in a physics simulator (MuJoCo)
Additional steps taken but not released as open-source are:
- model distillation
- training high-level policy that reflects tennis gameplay (ball tracking, shot selection)
- sim-to-real transfer moving final model onto a robot
You would partner with Schwartz Tennis Center to bootstrap the real human play video data used to (1) categorize a larger variety of play styles the robot can learn from (2) fine-tune the general purpose video model to a particular environment, perspective, or video device, using diffusion models that alter each frame of the simulation video to match the target environment. It’s about developing a data flywheel.
Once an accurate and successful model exists, you would use NVIDIA deep learning accelerator (https://nvdla.org/) to design a chip to do this for on low power, and explore deploying it in different form factors: with a solar panel, on a drone, etc. Live video feeds, line calls, and score tracking would stream directly to your phone through Wifi and Bluetooth during a match, and be backed up to the cloud using the phones as a proxy, to be accessable at any time.
What is the future of software? Are we sick of our screens? Is our most important work embodied in the real world? Are sensors and robots the future of the technology industry, is SaaS doomed? What happens when “I’m a coder” means “I tweak AI model architectures” instead of “I tweak database queries”? Is prompting doomed as an inexact science, will it be replaced by a training data set and reinforcement learning policy?
Who knows, but this is all pretty fun. I created a tennis court in the
simulator and watched the rendered model run around. I didn’t pull the trigger
on performing a training run, instead using human motion reference data, but it
would have cost me around ~$15-30 over 1-2h renting a p4d.24xlarge (8x A100
GPU) using the AWS spot-market.
I will confidently claim (and put my ignorance on show for fun) that:
- mobile devices are not going away and will be the primary interface to future software (voice, video, text).
- There will be an explosion in bespoke ML models trained on all these new GPUs and a corresponding explosion in low-power custom chips to run these models.
- robots will become very capable very quickly, be packed with sensors, and will communicate to us through our phones. The primary challenge is manufacturing and mechanical engineering, not intelligence.
- physics simulations (and their derivatives) will gain a larger percentage of GPU cycles in data centers once LLM improvements become so impressive that additional training provides diminishing returns to capability, or put another way, demand for LLM tokens will slow due to technology improvements and saturation of use cases.
Cloud Assignment Development Process
I’m concerned that my development process for cloud assignments will not scale beyond me, or be easily inherited by other instructional staff. In fact, I’m quite certain of it. Let’s list some challenges
- the course is managed with some parts in the instructional site and others in my git repository.
- juggling multiple Docker images for Gradescope and instructional site to power each cloud assignment.
- ad-hoc methodology for navigating assignment tasks and progress
- ad-hoc generation of test steps to verify assignment tasks
- re-inventing the wheel between cloud assignments due to no standardized methodology.
- the autograder script is tested against a reference solution stored in git and deployed in my own account, it is a mostly manual process.
If this course continues to move in the direction we’ve established, we’ll need to build additional tools that help instructors maintain the assignments. Let’s list what assets an assignment needs, and consider what any additional tools may look like.
Assignment deliverables:
- Assignment solution document: A text that painstakingly details the exact steps a student should take to complete the assignment. Should be comprehensive and a accurate representation of a student’s experience of completing the homework.
- Reference solution: the final codebase needed to complete the assignment
- Starter code: A skeleton of files a student is given at the beginning of the assignment.
- Student assignment guide: This is what students receive as the assignment text, omitting implementation details which become part of the learning experience for the student.
- Test script: a python script that verifies all important properties for every task in the assignment.
- Cost estimate: a cost breakdown of running the cloud assignment for N students over N days.
- Supporting Architecture: application code, ansible playbooks, and terraform configurations for any supporting software that enables the cloud assignment.
Helpful tools for instructors:
- Snapshots of the solution in different states, so we can run integration tests that verify the assignment still works (there could be API changes with third-party SaaS or AWS that affect the completion of the assignment).
- An AI test run of the assignment, so it can raise issues without a human having to go through each step. Requires access to a web browser, command line, and authentication to required services.
- Extend Obsidian plugin so assignments incorporate its native knowledge graph features.
- Assignment Laboratory: user interface for ai-assisted human design of a new cloud assignment. Will be a multi-stage process: ideation > implementation > verification > versioned release, and will orchestrate the different tools and agents. There will have to be some awareness of an assignment series, or conceptually connected assignments that refer to each other.
Student Experience:
- Drop Gradescope in favor of using the instructional site.
- They start an assignment like they start a chat prompt. With any question they have in mind. And the course assignment AI will answer. And introduce the cloud assignment goals during the release period, and guide the student through completing all the tasks, teaching them along the way. This is a rich data source to assess learning outcomes and student engagement.
- I’m reminded of my time at a Montessori school, where I was given a list of tasks to complete, but I chose what to work on when. I was graded not on whether I completed a particular task from the list, but rather if I completed sufficient tasks.
Regardless, the assignment development process should be standardized and fully integrated with the instructional site.