Week 12
4,970 words · 25 min read
Summary
3/30 - 4/5
Meetings
- 3/31 3:30-5:00PM Tuesday, 1-on-1-on-1 with Prof. Adams and Grace Lingley
- 4/3 9-9:30AM Friday, RCAC meeting with Prof. Adams and Dane Deemer
- 4/3 1:30-2:30PM Friday, Instructional Team Meeting
- 4/3 2:30-5PM Friday, Weekly Office Hours
Accomplishments
- Cloud Assignment 3 finished with 874 submissions and 53/68 (78%) completion rate.
Cloud Assignment 3 Retrospective
This assignment took 2/3rds less time to complete than the last. However, students procrastinated this assignment about 25% more, almost half of all submissions occured on the due date, and the average time a student made a submission shifted a few hours towards night. 78% (53) of students achieved a perfect score, the exact same as Cloud Assignment 2.
Assignment Analysis
Let’s take a look at our Cloud Assignment analysis page.
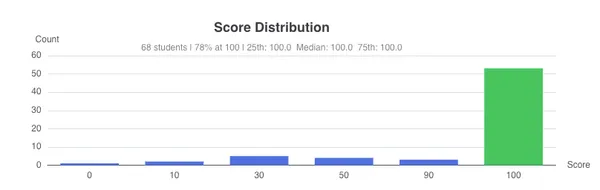
Average time was shorter this cloud assignment, and the confidence interval is tighter.
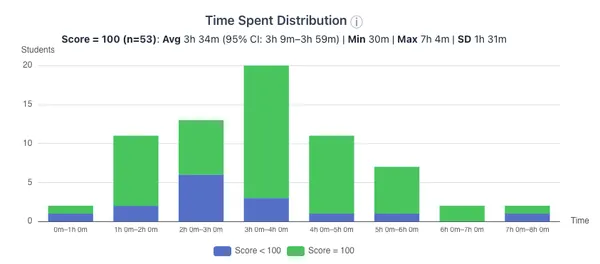
I’ve added our class time to the course data model.
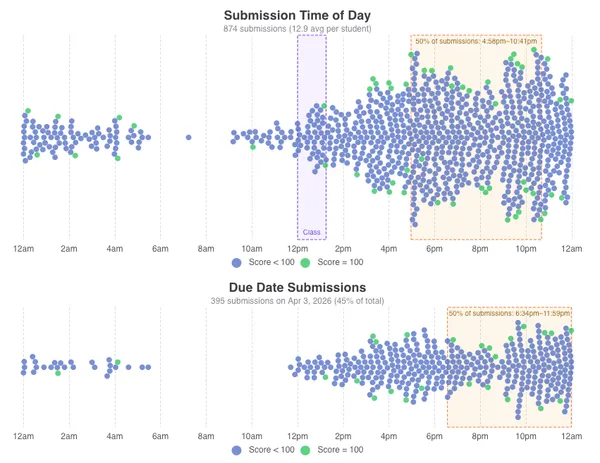
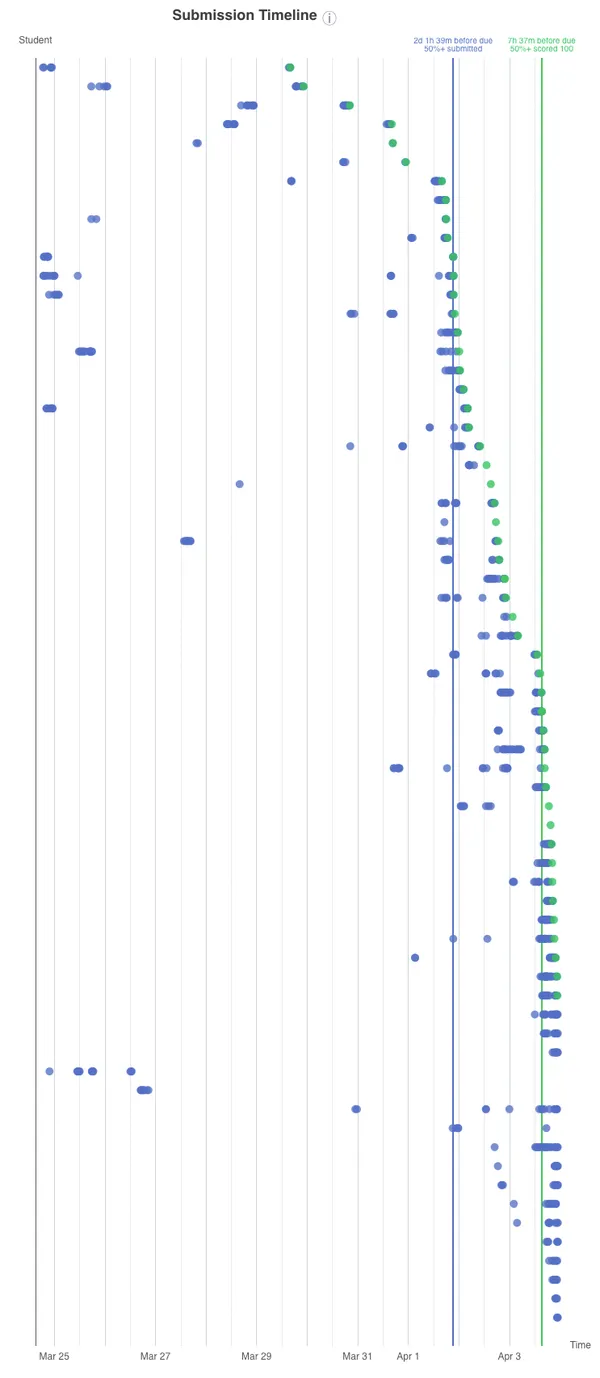
The submission timeline chart nows displays vertical lines showing when 50% of students submitted or completed the cloud assignment, marking how much time before the due date the event occurred. 50%+ of submissions occurred 2d 1h 39m before the due date, and 50%+ of competions occurred 7h 37m before due.
We now have a Student Planning section, where I provide actionable recommendations for students to improve their score. I want students to improve by helping them manage their time more effectively. Computer science assignments are hard to judge how long they’ll take. By examining students who scored a 100 on the assignment, and taking the median of how many days before the due date they started, the number of working sessions, and the time spent per session, we can give data-driven advice to students on when to start working and how much time to expect to spend.

Looking at the data, the advice for Cloud Assignment three is very reasonable: “Start at least three days before the due date and plan three working sessions each about an hour in length.” I’ve already shared this with the students in Ed.
Characterizing Student Performance
I’m always looking for measurements of how students compare to each other, so I can (1) identify what adequate class performance looks like so I can help students manage their assignment workload, and (2) identify outliers, or inadequate performers, so we can decide to take pro-active action to help a student or reflect on our assignment experience more broadly.
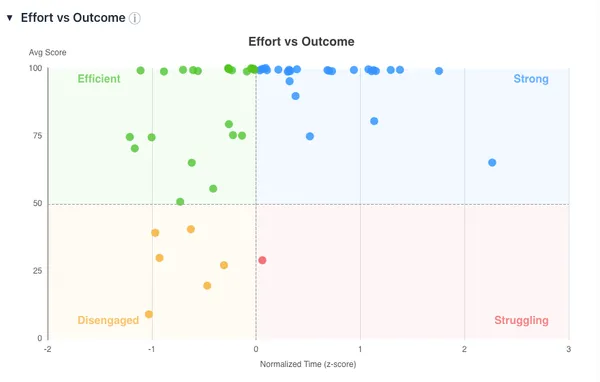
Effort vs Outcome compares students scores and estimated assignment times averaged across assignments, separating students into four quadrants. We do not need to worry about most students in Efficent or Strong. Outliers in Efficient suggest cheating, outliers in Strong indicate conceptual misunderstanding or inability to satisfy assignment pre-requisites (tools, hardware, permissions, money). Disengaged students are your classic C-students, to improve their performance you have to address and encourage them as a group. Struggling students merit individual attention. They are spending time on assignments but persistently failing.
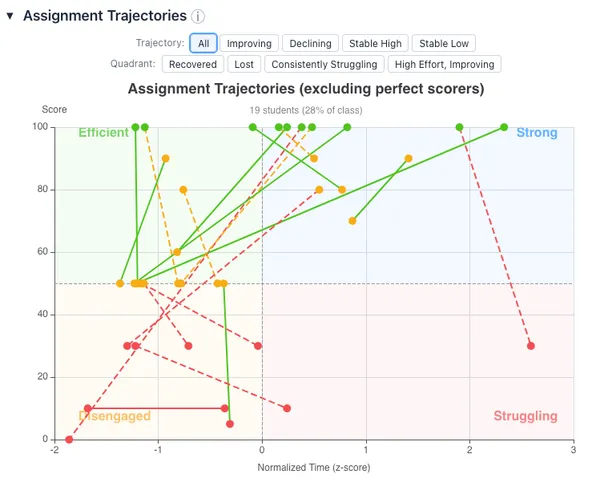
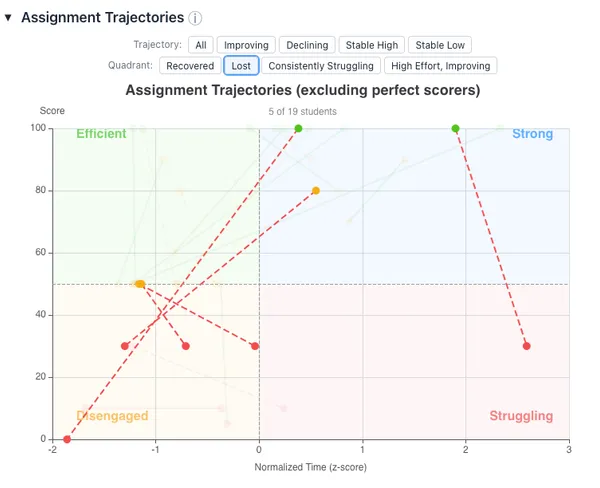
Nineteen students (28% of the class) do not have a perfect score on both CA2 and CA3. Assignment trajectories demonstrate how those students performance changed between cloud assignments. I’ve categorized students into groups based on trajectory features and quadrant features. I’ll discuss the features with the largest number of students: Improving, Declining, and Lost. Eight students were Improving and saw their score increase from CA2 to CA3. Ten were Declining, and saw their score decrease. Five are Lost and scored significantly worse on CA3 than on CA2.
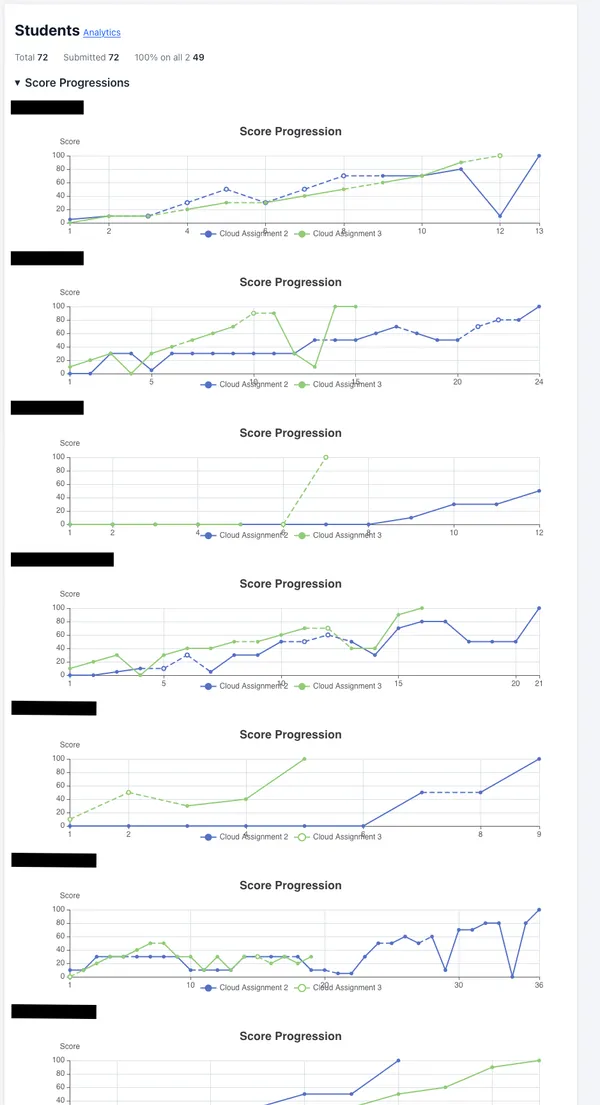
I also collect the score progressions for individual students in a chart sequence on the student list page.
API Data from “Gossip Squirrel”
CA3 required special instructor-hosted infrastructure to enable in-assignment features, namely, a DNS interface for students and the coordination server for the gossip protocol. I’ve realized this may be part of future assignments, and is another opportunity to collect data on student engagement with the assignment.
I created a CA3 Analytics Dashboard in the instructional site to demonstrate different engagement data visualizations.
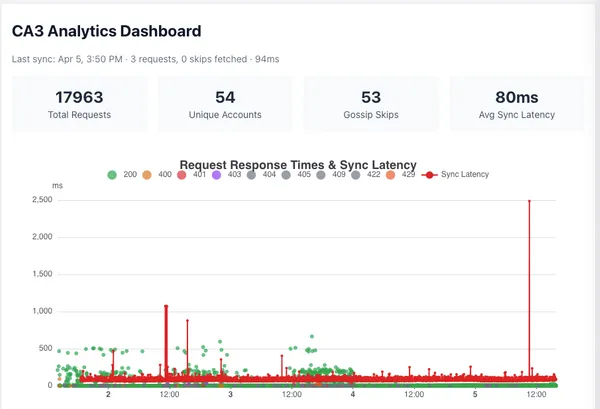
Performance was very stable, no errors and average response time <100ms. The
API server was a Python server using the FastAPI framework with a SQLite
database. It exposed an /analytics endpoint to sync data to the instructional
site. Authentication was enforced on the student side using their AWS Account
ID and External ID, and on the instructional site side with a secret API token.
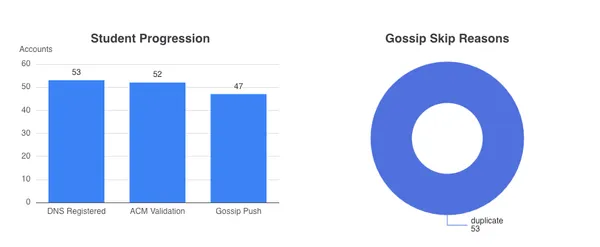
It’s fun to see what domain names students chose for their deployment.
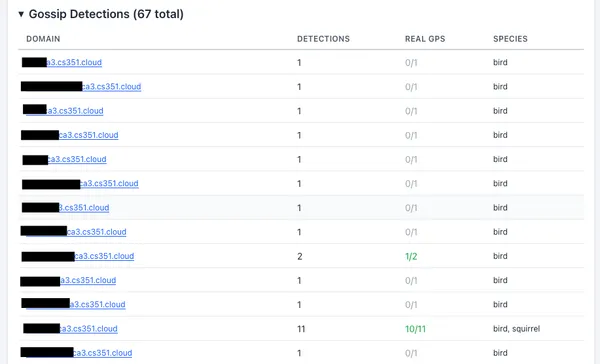
The Gossip feature of the assignment had low participation. Only two out of 53 students uploaded their own location enabled picture. I had hoped more of the class would have made an effort to take a photo of a bird or squirrel on campus. Next class session, I would demo the feature in class to encourage students to try it themselves, I didn’t encourage them at all really this semester.
I also kept a live activity feed so I could debug any student issues that came up, but I didn’t need to use it.
Ed Issue Summary
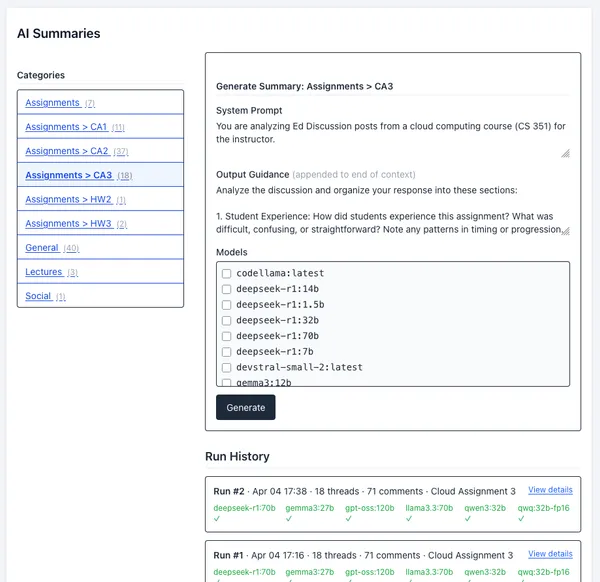
I’ve improved the AI Summary interface for the Ed discussion board. You can select assignment categories, then trigger a run of multiple models at the same time.
Remember, LLMs take on the tone of the content they summarize. This assignment was a success for most students. Students who post on Ed are generally exceptions encountering issues. With that said, I found Gemma 3’s analysis the best. let’s examine its high-level view of the student experience of CA3.
Student Experience: Initial stages (Part 1 setup) seemed relatively smooth, with questions focusing on clarification of due dates (#98) and initial confirmation of tools being in place. However, as students progressed, particularly into Part 2 and the more complex integration of Terraform, Ansible, and image/model updates, the difficulty increased significantly. Several students reported issues with infrastructure setup and configuration, leading to frustration and attempts to restart from scratch (#123, #125). There’s a clear pattern: initial enthusiasm and understanding at the beginning, followed by increasing complexity and more frequent issues requiring support. Students seemed to appreciate the detailed assignment documentation, but the depth of integration required between multiple tools proved challenging. The late-stage issues suggest that time management was also a concern, as one student admitted to running out of time and attempting to revert to a previous submission (#129).
The summaries also include an anaysis of (1) Common Issues & Errors, (2) Assignment Text Improvements, and (3) Instructor Action Items. It’s nice scaffolding to kick start a reflection on a Cloud Assignment.

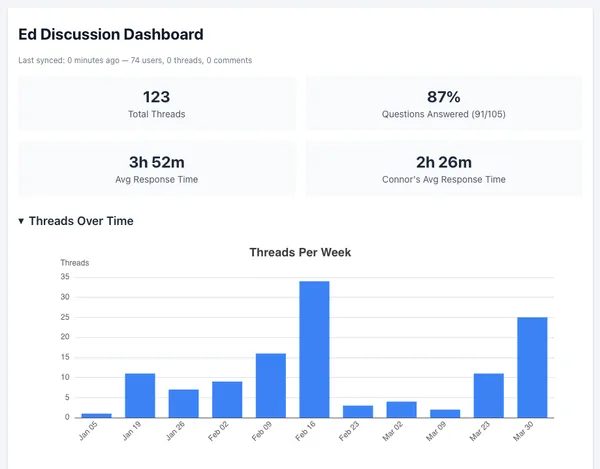
I also had Claude summarize Ed usage data. This is easy, because all Ed data is synced to our instructional site, even more than the usual interface. I’m able to track deleted posts, determine what time posts occurred, and derive additional statistics.
CA3 has roughly half the volume of CA2 but higher reply density per thread (4.9 vs 3.6). The AI auto-reply system was active for CA3 (21 runs, 18 bot comments synced back), while CA2 had minimal AI involvement (3 runs, 0 synced). Answered rate is much lower for CA3 (39% vs 81%), and engagement (views, votes) is down.
Assignment Flaws
The terraform init section was misleading, I had re-organized the assignment
and it became out of date. The sequence of commands needs updating. For
example, I asked students to inspect their terraform state file before they had
generated it.
Sometimes its not clear when a student is asked to perform a task. At the moment, the cloud assignments test student’s reading comprehension. I don’t think this is a big issue, and we can improve this with better automation anyway.
We need more direct feedback from students after each Cloud Assignment.
Office Hours
Office hour participation was low. I had one student attend. It was valuable to watch her move through the assignment, and be able to ask her questions.
Students who used Ed reply bot after my office hours on the last day:
- ████████: He has been struggling in the class, 30/100 on last two cloud assignments. Posted at 9:45PM after making 9 submissions, then made four more submissions ending at 11:30PM a lower score than he had at the time of the Ed post.
- ███████████: he achieved 50 points, and is struggling debugging Docker issues in cloud assignments. He has a Mac. He has been taking twice the time on Cloud Assignments than other students based on his estimated session times for CA2 and CA3. He reached 100 points on CA2 with twice as many submissions as on this assignment.
- ███████████: She posted to Ed at 8:32PM, at that time she had 19 submission attempts and 90 points. She made her 20th submission at 9:12PM and received a 100.
- ██████████████: She visited me during office hours, and over 2.5 hours she reached 70 points. She finally achieved 100 at 9:20PM after four more submissions.
Half of last minute Ed posters achieved 100/100. It’s not clear if the auto-reply bot helped them, neither of them responded to any of its replies. Of the other two students, only Andrew replied to the reply bot, he used it three times.
Grading High Scores
I’m promising students we give them their highest recieved score, so I have to make sure thats the case. Do I need access to brightspace grading or do I already have it? I might be able to manually do this in Gradescope, it wouldn’t take much time.
Data-driven CA4 Groups
For CA4, any student that didn’t get 100 (15 of them) should be spread across all the groups. We’ll do a random grouping of the full scorers, and then distribute the partial scorers.
The groups will schedule a time to meet with me for 15 minutes every week, either in-person or on zoom.
CS351 Ed ReplyBot
I’m experimenting with automating Ed replies. I’ve implemented a AI replybot, where it responds to every thread, and if the student responds back to its reply, it will continue generating responses, like they are having a conversation.
Originally I was using deepseek-r1:70b, its a reasoning model that gave high-quality responses, but it has high-latency on the GenAI cluster, requests were timing out or taking ~5 minutes to complete. I switched to gpt-oss:120b which is quite fast, ~10s of latency, and medium quality. It tends to guess and mislead students for two reasons: (1) it doesn’t have reasoning enabled (2) it doesn’t have the context of a students code. It’s a great model to use for this experiment though, very reliable, it likely has more cluster resources allocated to it than other models. I’ve just recently switched to gemma3:27b, I really like its writing style. I’m realizing different models are better at the “frontend” (talking to users), and others are better at the “backend” (adhering to instructions).
There are some limitations to my implementation. (1) student posts can contain images. The bot will only see the URL of the image, not the image content, and it has no tools to inspect images. This makes it harder for the model to understand the full context of the student question when students share screenshots of their terminal. (2) The RCAC cluster enforces a rate limit of 20/calls per minute.
I’ve considered some other improvements: (1) up-to-date open-weight models like Google’s Gemma 4, StepFun’s Step 3.5 Flash, and Kimi’s K2 Thinking, all high-performing open-weight models. (2) I could keep a running AI generated summary of all posts and issues for a category on Ed. The summary would have two sections: a summary of un-resolved posts, and a summary of resolved posts, giving the AI a running idea of the collection of issues students are experiencing now and how previous issues were solved. Each new post and comment will get sent to the AI with the existing summary, and the AI returns an updated summary that incorporates the new information, which will then be included as context by future AI auto-replies. AI software systems are a new way of thinking about data!
An additional feature I implemented was transforming the markdown that LLMs emit into the XML format Ed uses for its comments, so that an LLM natural output format looks nice. This is more robust than getting the LLM to try to output Ed’s XML format, something it hasn’t been trained on. Parsers are everywhere in AI applications.
Let’s examine a student’s interaction with the AI auto-reply feature. ███████, posted Friday morning while I was playing tennis with a Terraform question. He had correctly noticed that Terraform was going to delete and recreate the credential he had made and attached to an EC2 instance manually. He was wondering if this was intended and if he had to modify the Terraform code to avoid this. Now, the AI replied, but because it lacked the source code in its context, it misled him by requesting that he update the provided Terraform code. Then, he replied to the AI message with more debugging information! This is exactly what I wanted!
Hilariously, he ended his message with “I’d like to talk to a human if possible.” Its important we provide frequent opportunities for students to interact with instructional staff throughout the semester, even if they don’t take advantage of it at first. We should not automate all human interaction, we should provide students tools that give them feedback. ███████ was clearly frustrated, and part of that is he is working on the assignment on the last day, part of that is the AI output is misleading and quite long (the classic “AI sounds right but is actually wrong”). Clearly, the reply bot’s prompt should be updated according to student feedback on how helpful the response was, but the mechanism is not clear.
I noticed students ask a question on Ed, then delete their post. This happened 3 times during CA3. These types of posts the ReplyBot is perfect for. They get quick feedback without feeling embarrased waiting, and the rest of the class gets to benefit from their question, improving class success rate.
Automating Cloud Assignment Development
A past weekly report discussed splitting Cloud Assignments into two parts. The benefits were (1) practical, splitting work into smaller chunks with more frequent due dates, and (2) structural, “Part 1” implements a reference architecture, while “Part 2” implements an application feature enabled by that architecture.
Now, how do you automate creativity? It’s hard creative work to create a cloud assignment. When you have a hard problem, split it up into smaller easier problems. “Part 1” is actually well-described. “You will implement N-Tier architecture” simply means Part 2 will have a proxy, application server, and database it can use to solve a problem.
Let’s describe additional architectures:
- container cluster architecture: Kubernetes
- large database cluster: analytics, reporting
- GPU cluster: video rendering, AI/ML
- microservices: lots of variety
- sensor network architecture: IoT, cloud networking
- scientific computing clusters
- CI/CD Pipeline: managing software artifacts
- Job queue: auto-scaling workers
An instructor would select an architecture that has been developed separately, and the AI will adapt that architecture to help them create a “Part 2”.
I’ve discussed ideas for “Part 2” earlier, but I believe this is the tougher problem. Solving the easier problem of “Part 1” reference architectures is the right starting point for creating a curriculum development tool.
Claude Code Source Code Leak
Claude Code had their source code leaked because they accidentally published Javascript source maps alongside their new build release. We can use Claude Code as a reference point for how to create a high-performing agent harness to drive the student experience of cloud assignments.
RCAC Meeting
We had an RCAC meeting on Friday 4/3 at 9am with Dane Deemer. I reached out on 2/27 at the behest of Justin Gillingham to seek help and resources with Cloud Assignment 4.
Two topics were discussed:
- Kubernetes support for Cloud Assignment 4
- Deploying new AI models to the cluster
Dane has been at Purdue since 2020, he does computational biology. He’s been at
RCAC since October 2025. They use the Rancher GUI to manage their Kubernetes
clusters. There are two clusters at RCAC: Anvil, an NSF resource (Dane works on
this one), and Geddes, a Purdue cluster. Dane suggested Geddes is the better
choice for this class. Part of the Rancher GUI provides a link to a kubectl
configuration that lets students deploy directly to the cluster. They can use
“Minikube” for running a cluster on their local computer, then deploy it
separately to RCAC.
We informed them we will have ~15 student groups who need access to the cluster, and suggested resources on the scale of ~8GB RAM and ~80GB disk each. The assignment will run for 17 days, Dane suggested it should be easy to get a month of access.
They have some type of to enable DNS for custom domains, we should be able to take advantage of that. They have IP whitelisting and other firewall tools we can configure for the cluster if needed. Purdue is pushing RCAC customers to use their object storage, built using a Ceph cluster that provides distributed block storage.
Dane can be reached by email, ddeemer@purdue.edu, and he said he’ll reach out to the Geddes team and the team running the GenAI studio. I suggested adding Gemma 4 to the cluster and explained to him how we are using GenAI studio to help manage the course.
I have a good feeling about this, we’ll see!
Supporting Student Success
When I mentioned the estimated time to complete Cloud Assignment 3 in class (it should take 2-4 hours), I saw a female student breath a deep sigh of relief. Giving students some indication of how long an assignment takes so they can manage their time more effectively will reduce a lot of stress that students have.
I’ve discussed instructor tools, and student experiences of assignments, but what other student tools can we provide? I have some ideas:
- Connect their class schedule to the class chat experience, have the AI help them find time to (1) visit office hours (2) work on assignments (3) study for midterms. We can develop a prompt that advises students, informed by curriculum research, which represents the department’s philosophy for how to study and succeed in Computer Science at Purdue.
- Have class polls active in their profile, asking questions like “What office hours are best for you?” that help instructors understand how to schedule help resources.
Gradescope failures
We had gradescope failures. One of the issues is there are not enough resources
for job queue on Prod. I will upgrade. The analysis document is in the repo:
docs/2026-04-02-ca3-autograde-timeout-analysis.md
I’m using the AI to analyze past usage patterns, and judge how much we need to scale the service to accommodate the increase load. Call it an AI-assisted informed guess. It’s looking at the past peaks in load on the last due day, to judge what we should expect on Friday as students rush to submit. At some point in the future, this process will be automated, and auto-scaling will happen based on past usage data automatically.
This task is made easier because I tracked so much data. If (1) you track the right data and (2) the AI has tools to query that data, you can answer a lot of tricky questions quickly and robustly, and you pave a path towards further reflection and automation.
The problem was that autograding jobs were starved of resources due to high-latency AI jobs filling the single queue. The fix was to increase the priority of autograding jobs relative to AI related jobs, add another worker process to the worker node in production, and increase the thread limit per worker.
We had no more errors after those updates were deployed.
Refunds
A student spoke with me after class, he received a bill from AWS for January, February, and March. He’d like to be reimbursed if possible. Here’s are the totals for each month:
█████████: (███████@purdue.edu)
- January: $0.02
- February: $0.36
- March: $2.12
- ~April: $0.25
It would be nice if we could generate a cost report alongside each finished cloud assignment, representing how much money it cost (1) students and (2) instructors to run the assignment.
Cloud Assignment Features
How can we make cloud assignments an exceptional student experience?
VibeCheck component for student feedback
Students can submit a sentence that describes how they feel at this point in the assignment, or in reply to a prompt. Other students can then vote on the response they vibe with the most, or add their own new response to the list. Rich source of student engagement data, while also giving opportunities for students to be fun and social within a class assignment, so they don’t feel so alone.
Before the assignment begins, instructors would create 2-3 VibeCheck prompts to ask the students at various points in the text. These VibeCheck prompts should be designed to answer a particular question the instructors have, to get feedback on ideas from students, or be an opportunity for students to have fun making memes. The assignment should always end with a VibeCheck soliciting feedback on the particular cloud assignment.
Having a meme VibeCheck is kind of like how the New Yorker ends each magazine with a “Submit a Caption” contest. It’s one of the best parts of the magazine.
At the end of the assignment, the instructors would review the leaderboard and reflect on their initial questions and the student experience of the assignment.
This is my leaderboard idea, but instead of best score, it’s best memes. There is prior art, the teaching assistants for CS 381 run a meme contest in the class Ed discussion board after every midterm exam.
Reflection on learning outcomes
During my impromptu office hours, I was helping a student, █████████, debug issues with the ECR portion of the assignment. I found myself listening to her experience, and guiding her through the assignment. I saw a small portion of the assignment through her eyes, it was illuminating. Clearly, we must sit with users and work with them through an assignment to improve the experience. I found myself discussing the <Reflect> section titled “Food for thought”. The section ask the student to reflect on the steps they took to deploy in CA2, and what they just did in CA3, and to compare the two. The point I wanted to drive home was that all the manual steps we performed in CA2 (docker build, make swap, set authorized_keys) is now done in one Ansible command.
What can we draw from this experience? A student was working through a section of the text. I narrated and guided part of the assignment for her. We landed on a <Reflect> component. I identified a key learning outcome that should result from that reflection. I asked the student to reflect, and we talked until I brought her to understand the learning outcome.
I thought this was a valuable learning experience, and I considered how I would use AI to scale this interaction to all our students, as I can only sit down and guide one student at a time. I believe the key is recognizing I wanted the student to state the learning outcome herself, so I could be sure she knew it.
If each assignment had a set of learning outcomes, we could make <Reflect> components for each one. As the student progresses through the assignment, accumulating points, the AI introduces the reflections. A reflection is a separate, but stateful conversation reflecting on the question posed by the prompt. The student has to converse with the AI by text or voice until they are able to state the learning outcome. The AI will teach the concepts and guide them during the conversation.
A student will gain points from sections separate from these reflections, reflections, but they must finish every reflection in the assignment in order to have the points count towards a grade. That means, reflections are required but get you no points, and if you don’t answer them all, you get a zero on the assignment.
Developer Website and CLI
This project would benefit from having a web application and command line interface product-izing how the instructional site is developed. Basically, build a web app that helps you build a web app.
Will help developers onboard if we get interns, teaching assistants, or staff. Enables flywheel for AI-powered product development by creating and providing tools specific to our use-case for use by coding agents.
Tools:
- query production application logs
- query production database
- run against test infrastructure
- run commands in application containers
- manage development servers
- safe deploys with rolling deployments, integration tests, and risk analysis
- secrets management for development team
- feature flags or system parameters
- UI change tracking
- automated UX design reviews
I’ve noticed the AI guesses at commands and working directories a lot. It loses track of where it is in the file system, and when there are multiple ways to use a tool, conventions can be ambiguous causing it to fail until it finds out “how we do things around here”.
If one person continues to work on this application, it’s practical if tools remain ad-hoc. I believe there is real value in building a interface to query application logs, however. The instructional site has a long way to go before its properly observable.
For all our progress, the instructional site remains a proof-of-concept. There is a lot more work to do on it.
UI Polling traffic
Website traffic went from ~200 requests/day to ~20,000 requests/day because I implemented one user interface feature. I added a CA3 infrastructure analytics page that polls the server for updates, and left 1 tab open all day. I’ve separated this traffic from normal user traffic in the “Request Log” page, it’s labeled as “HTMX”, the javascript library used to perform this polling update.
Real-time updates are good. I want the website to check for updates. Clearly, real-time updates massively increase request volume to the application. How do we mitigate risks as we add more real-time features?
- have a global polling loop on the instructional site web page so polling events are batched and request number is minimized. We will collect metrics on load and request volume based on the polling parameters, and surface it in a UI, so we can tune that polling interval/behavior over time.
- Add appropriate HTTP headers to cache HTML partials used in real-time update requests, reducing load on origin servers. This may be fine tuned according to SLAs (update frequency) and projections (active daily users).
- create our first automated benchmark test, which load tests only those pages with the real time polling features. These load tests are actually feasible: they don’t test complex business logic, they simply test if polling requests for updated state complete successfully and quickly. Those are easy scenarios to create with database mocks, we already do it for our unit tests.
This class is running pretty well on two t4g.small instances (app+worker), I’m impressed. We’ve bumped up against the limits a few times now, but most of the time we’re feeling cozy.
Expanding Submission Materials
I met with a student, ███████████. He was stuck at the “Container Repository” section. He was having trouble pushing to the ECR repository. He had created a docker compose, and instead of building Nginx, he had been building bird.ai. Bird.ai is too big to fit within AWS Free Tier limits, and too big for ECR public repository limits. This is an easy mistake to make, its logical to assume bird.ai is the next part to work on, even if the assignment states to build the “proxy”. In fact, I was originally planning to make this the path through the assignment until I ran into AWS free tier limits and had to change my plan.
Why was AI unhelpful in debugging this? The error did not lie in his submitted credentials, AWS snapshot, or EC2 instance state. The error was in the docker compose file on his laptop. Andrew made an interesting suggestion. Why don’t students submit their whole working directory to the autograder to get graded, not just the credentials file?
I like this idea for three reasons:
- We can verify student file structure matches what is assumed by the instructions in the cloud assignment.
- We can provide additional checks and assign points based on their written code, not just deployed infrastructure, even running unit tests easily! (which I’d like to do now but is tricky in our current setup).
- We can provide all their code (or a diff against the starter code) to an AI to help them debug. This is the missing piece for any GenAI models to have the full context of what they’ve been working on.
I might implement this for Cloud Assignment 4, I have to think about it. It will be a good way for us to inspect the vibe-coded application code the students created, and after their presentation give them targeted/generated feedback based on the actual application code they submitted. Basically, finish the assignment, present your demo, and then receive a code review as feedback.
How to inspire new cloud assignments
There are a few universities that introduce Kubernetes in their computer science coursework, I’ll highlight a few, I’m sure there are more.
Undergraduate courses:
- UPenn: “DevOps” (CIS)
- UT Austin: “Cloud-Native Computing” (CS)
- UIUC: “Distributed Systems and Orchestration” (CS)
- Tufts: “Cloud Computing” (CS)
Graduate courses:
- NYU: “Cloud Computing” (CS)
- John Hopkins: “Cloud-native Architecture and Microservices” (CS)
- University of Chicago: “Introduction to DevOps” (MPCS)
None of those courses have our auto-grading approach. Student solutions are manually reviewed as they have small class sizes.
How do we test out new cloud assignment ideas? We host a hackathon in the Fall, where students select from 1-5 new cloud assignments, spend 1-2 hours going through them with a group, and spend the rest of the hackathon using what they learned from the assignment to build whatever they want. At the end of the hackathon we get data about (1) what new cloud assignment is most popular with students (2) feedback about student experience of a new cloud assignment (3) issues highlighted in a non-graded setting way ahead of when the class would run them in the spring. Additionally, this hackathon acts as advertising for the Spring class, and would increase enrollment and visibility.
One of NYU’s projects is quite interesting. It benchmarks different ML algorithms across hardware so you make informed system architecture decisions. Similar to us in that they have students deploy a ML microservice on Kubernetes.
Inspired by NYU’s class, we could create an additional Cloud Assignment series. It will emphasize benchmarks and observability for software deployed on different cloud systems.
- Assignment 1: Load-testing and monitoring web applications and job queues (traces, logs, metrics)
- Assignment 2: Benchmarking and performance tuning different ML model types (CNNs, LLMs, etc.) across different cloud provider hardware types.
- Assignment 3: Benchmarking and running scientific simulations (physics, monte carlo, computational biology) on RCAC Geddes Cluster.
- Assignment 4: Kubernetes observability and resource optimization.