Week 13
1,860 words · 10 min read
Summary
4/6 - 4/12
Meetings
- 4/7 3:30-5:00PM Tuesday, 1-on-1-on-1 with Prof. Adams and Grace Lingley
Accomplishments
- Cloud Assignment 4 released
CA4
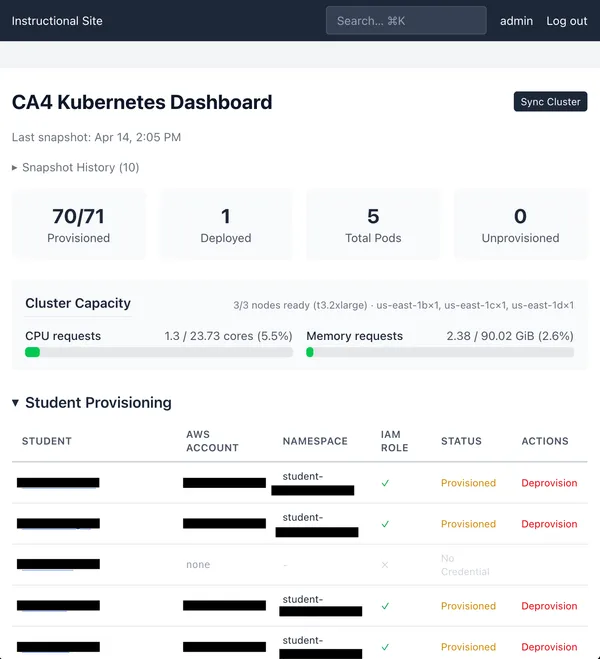
Cloud Assignment 4 took a lot of iteration. The Geddes cluster was unwieldy (students would have to use Purdue VPN), on-par cost-wise with AWS EKS (final accounting TBD), and fatally, had scheduled downtime during the two busiest days for student submissions this assignment.
I transitioned to AWS EKS and built a CA4 dashboard that provides monitoring and control of the assignment experience for students.
I then designed the CA4 assignment to be a straightforward Strangler Fig migration. We had discussed (1) making this assignment a group assignment, and (2) making the second part creative, where students either deploy to the Kubernetes cluster an open-source application and create an RFC for a contribution to the project, or vibe-code their own application and create an elevator pitch demo video for it. I was time-limited and we reduced scope, and I believe the student experience this semester will be the better for that.
Our EKS cluster provides a namespace for each student, representing a claim on resources in the cluster. Student’s authenticate against the cluster using their personal AWS account. Because we know their account ID, we can grant them cross-account access limited to only their namespace and an ECR repository, and nothing else in the instructional account. A student namespace provides 1.5vCPU and 2.5GiB of RAM on average, with the ability to burst up to 6vCPU and 9GiB of RAM. Students are also limited to 15 pods, 5 services, and 3 volume claims.
The baseline cluster capacity rests on three t3.2xlarge nodes, which give us the best bang-for-buck capacity vs cost for this assignment. t3.2xlarge nodes are Intel Xeon Platinum 8000 processors with 8 vCPU, 32 GiB memory, and 40% baseline performance, costing $0.3341/hour. I added auto-scaling, primarily as a cost control measure, as the majority of student resource use occurs in the last three days of the assignment period, and I didn’t want to manually manage the cluster size. The maximum size of the cluster is set to 13 of the t3.2xlarge instances.
In some ways this assignment was harder to develop as I did not have much Kubernetes experience, it took a lot of iteration to get to a good final state. In some ways, it was easier to develop , because I didn’t have to keep everything in the free tier, I simplified the N-Tier architecture for this assignment, and Kubernetes provides a lot of primitives as part of the platform that AWS makes separate paying services (no wonder AWS wants you to use ECS on EC2 rather than EKS).
Claude got a lot smarter again. It handles large contexts flawlessly, is exceptionally detail-oriented, and adjusts to varied tasks very well. And now it’s good at understanding how long a task will take an assignment (I saw it debating whether a student could write a Dockerfile in 30 minutes and it decided it was unlikely). These AI are becoming very good assignment writers, and good at estimating the time to perform a task (and will become better with data). Again, my crazy idea is becoming more real.
A lot of the final prose of this assignment was written by Claude as I don’t have enough Kubernetes experience for certain explanations. I had it examine my past assignments to understand the tone to use and pedagogical flow. When I examined its output, I was impressed, and I only had to edit and refine about half the content. Part of my process for driving assignment development revolved around an assignment log, where bugs and fixes were recorded across iterations, in essence a history of the development process. I also had it create a thorough assignment walkthrough used as reference for the final assignment document text and autograder test suite. I believe a few conventions like these will make assignment development much easier.
When part of an agent harness, I believe a systems software assignment could be developed and deployed to students in 2-8 hours, plus any time for brainstorming. The deliverables would include an assignment document, starter code, supporting infrastructure, and an autograding script. It would automatically hook into the shared assignment infrastructure that performs data collection and produces the assignment analysis page.
More assignments should focus on Kubernetes. It’s role is expanding past containers into VM management and ML training/inference architecture. It’s such a big topic that one assignment is not enough. I was unable to discuss etcd, how Kubernetes schedules containers, container networking, and many other topics to constrain assignment size. I think 3 Kubernetes assignments would be appropriate and I would suggest the following Cloud Assignment series for next class section:
- CA0: Setting up your AWS account by deploying bird.ai to an EC2 instance (combining this section’s CA0 and CA1).
- CA1: Introducing containerization and our first new app feature (this section’s CA2).
- CA2: N-Tier Architecture using Ansible and Terraform (this section was CA3)
- CA3: Strangler Fig migration to Kubernetes (this section’s CA4)
- CA4: TBD Kubernetes assignment
- CA5: Group assignment deploying to Kubernetes
Final Presentation Outline
I think I might be able to get this done by quiet week, I’m really not sure.
- Overview of Senior Project
- Goals and Accomplishments
- Cloud Assignments (bird.ai, submission data analysis)
- Instructional Site
- Student Engagement and Success metrics
- Conclusion
- Cloud Assignment Experience and Pedagogy
- Bird.ai application evolution
- Assignment Architectures
- Learning outcomes (assignment data analysis)
- Lessons learned guiding future assignment development
- Ideas for future assignment series
- Instructional Site Infrastructure and Automation
- Use of Claude Code to develop site and assignments
- Architecture of Instructional site
- Architecture used to support assignment experience for students
- Ed scraping, category summarization, and auto-reply bot
- Astro for writing cloud assignments, integration with Obsidian plugin
- Challenges, evolution, and opportunities
- AWS Free Tier (contraints, cost monitoring)
- Gradescope vs. Self-hosted infrastructure (integration details, discussion of downtime)
- Automation to reduce technical demands for instructional staff.
- performance improvement work (load balancing, work queue optimization)
- GenAI RCAC
- monitoring and observability
- Discuss history of feature implementations, and how each enabled the next (e.g. submission tracking + Ed syncing + assignment storage/obsidian plugin = enabled ed auto reply both with full context)
- need to dig through weekly reports
- Future Work
- AI-driven cloud assignments
- Student tools for success
- Enhanced data collection and analysis
- Automating Cloud Assignments Part 1 (reference architetures, pre-instrumented VMs and software for monitoring/autograding)
- Multi-cloud
- Institution provided accounts for students
- Metered and monitored AI access for students
- Onboard students to instructional site
- Course management features, integrations with other tools (brightspace)
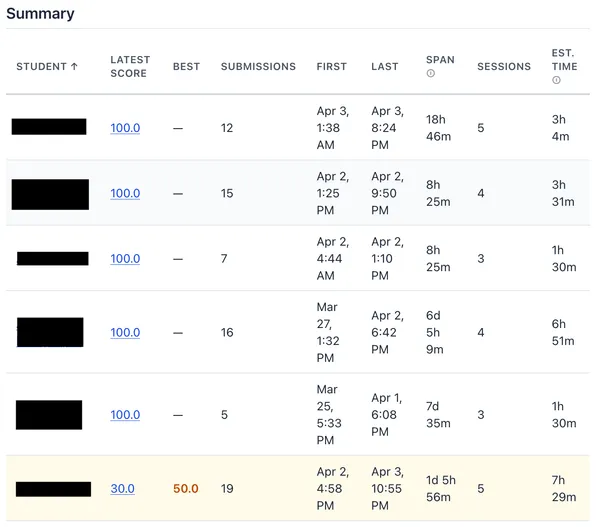
Student Best Scores highlighted
A student’s last score may not be their best score. I’ve highlighted students who meet that criteria on the assignment detail page, to identify what students need manual verification of a final Cloud Assignment grade.
Learning Outcome Studies
You could test out AI guided conversations towards learning outcomes by asking lecturers to collaborate, using their class session to collect data.
Before the lecture, we ask the professor to identify one key learning outcome he expects for his students out of the material. During the middle of lecture, we’ll interrupt and have students go through an AI guided lecture reflection, and measure the content (we can anonymize if needed).
As part of the proposal for this study, I would have to clearly define the data I intend to collect, and the analysis and visualizations I will produce using this data, and share that with the professors we collaborate with.
We would perform these studies in a multi-disciplinary fashion, starting in the College of Science, but I believe the business school or liberal arts would be good candidates.
AI: The greatest opportunity for Teachers and Researchers
AI makes hard things easy. Now we can ask students to do harder things, and scale how we share information and crowd-source troubleshooting.
The physics professor at College of Science at Purdue won the Murphy award, a key reason was that he wrote a physics textbook that brought Quantum Physics to the undergraduate level. No one believed it was possible, now his teaching methods are global.
What are LLMs good at today? They excel at summarizing vast quantities of information, and communicating it to a user. What is teaching? The summarization and communication of information. My word, we have tools that teach intelligently. LLMs may not be able to write the perfect software (yet at least), invent a new kind of rocket, or fix your emotional problems, but it can definitely teach you new ideas and guide you through obstacles to understanding.
AI will be a rolution in teaching. We’ve been teaching the same way for over a century. The internet began to disrupt that, that’s where I learned software engineering, and AI is a force multiplier feeding off that initial disruption.
Universities are at risk of more and more competition. High schools are already banning phones because they can’t keep students’ attention. A university will not be able to ban phones or computers. So how do they respond?
Researcher’s work just became more important, they are at the forefront of knowledge. Procedural knowledge has been automated, not new knowledge. And knowledge has just received an incredibly effective new form of distribution. With distribution comes influence. Researchers will become more influential, if they can understand how to package and share their knowledge in new ways.
Let’s discuss computer science curriculum. Computer science assignments are difficult to develop due to a variety of student hardware and the rapid pace of change in software.
Student time spent on assignments increases significantly when they run into incidental issues with software configuration. Debugging a minor software issue for hours is not a good use of time now that we have AI debugging. Student time should be spent on conceptual problem solving and engineering plan implementation.
A centralized learning platform with AI analysis of issues students experience in real time helps instructors highlight issues with assignment assumptions and respond rapidly to unblock students on assignments. This is partly a question of distribution: how do we get updated learning materials to students? How do we communicate information that will help them succeed in a course? The other component, assignment progress summarization and analysis, is tractable, as my experiments in this course have suggested. An experiment with distribution was attempted when I implemented a student dashboard in the instructional site, but its realization as a class tool was blocked by email configuration constraints.
With new tools that can evaluate intelligently, can we invent a new style of exam? Is a multiple choice question on a test the best way to assess student learning outcomes, or is it simply the easiest way to grade a large class? This is the flip side to curriculum development, student evaluation. We’ve invented a new kind of homework assignment, a new way to teach. But we haven’t invented a new way to test. The instructional site has no concept of an exam.
To close, AI depends on high-quality training data. I believe universities are in a position to create that data. In our case, creating a data set of high-quality assignments different AI can be fine-tuned on or benchmarked against.
Purdue’s position as a research institution benefits from this. They can afford to hire instructional staff, whose focus is creating high-quality written materials that can be used as assignment structure, prompts, and training data, powering an agent interface professors or TAs will use to create class-specific assignments in much less time, and with much less need to be a talented writer or curriculum developer. Professors will be able to focus on being experts in their field, sharing their knowledge and perspective, rather than laboring over the mechanical production of teaching materials.