Week 14
862 words · 5 min read
Summary
April 13 - April 19
Meetings
- 4/14 3:30-5:00PM Tuesday, 1-on-1-on-1 with Prof. Adams and Grace Lingley
- 4/17 1:30-2:30PM Friday, Instructional Team Meeting
Accomplishments
- Cloud Assignment 4 in-progress (12/68 complete, 98 submissions)
Deliveries this week
Cloud Assignment 4 is humming along, it looks like it’s taking students about 2 hours at the moment.
I had to increase disk allocation to the nodes in the cluster. When a student reaches the final strangler fig portion of the assignment, they have to build and push a large (3-4GB) container image to the node. When the node only has 20GB, two or more of those images take up all space on disk. My integration tests did not discover it, because I tested with two student test accounts, not three. Nodes now carry 80GB of disk space.
The initial cluster for the assignment was over-provisioned. I had too much
redundancy, too much initial capacity. I had overshot the obvious scale of the
class, so I downgrade the EC2 instance type from a t3.2xlarge to a
t3.large, half the cost, and reduce the min cluster size to two nodes from
three. The installed autoscaler will do the rest, I’m curious to see how it
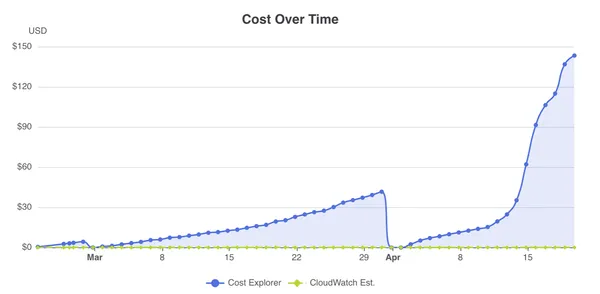
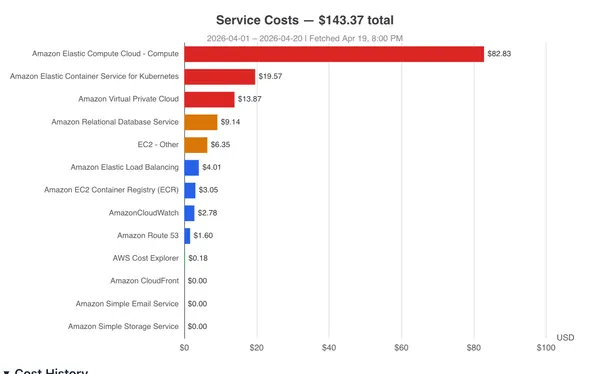
will handle the last minute submission burst. This change brought the estimated
cost to run the assignment from $500 to $200.
We have 3 students who are always the first to start. I’ve improved the Ed AI
reply bot to have the starter code and k8s cluster state in its context, which
should help students debug. The larger context has been causing timeouts in
RCAC GenAI Studio with gemma3:27b, so I implemented auto-reply retries,
falling back to gpt-oss:120b. Ed issues are minor so far, and the starter
code only needed a single file update after release to fix a bug. One bug and
12 perfect scores.
We’re just about at the amount of data, 120MB, that common workloads bring memory pressure in the db.t3.micro VM (2vCPU, 1GB of burstable memory), below our <100MB threshold. This DB has served us well this semester.
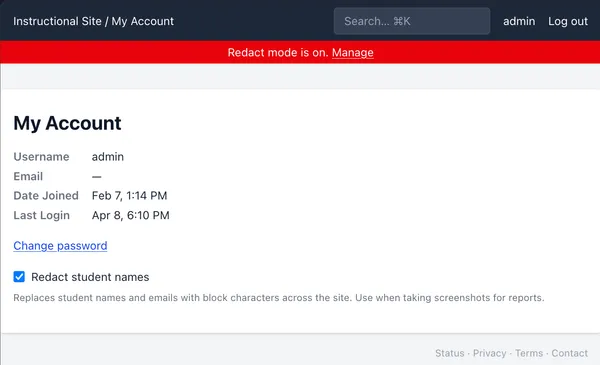
I’ve implemented a “Redact mode”, which obscurs all student names, emails, and IDs on the website. It’s off by default, but when the course ends, I will enable it by default, to respect student privacy. I will also anonymize those same identifiers in the database itself and remove any infrastructure snapshots and audit logs. We may also consider publishing the anonymized data.
It would be easy to scale the cloud computing class to double the number of students next semester. With the preliminary usage data, we can prepare easily for resource use by students, improve the assignments to address v0 issues, and use historical debug logs to improve student feedback from the autograder.
Perplexity, Jerry Ma
Jerry Ma, a West Lafayette High School graduate and VP at Perplexity AI, gave a talk at Purdue.
His opening slide show showed how open source model intelligence had caught up with frontier models this year. He followed with an examination of an abstract computer consisting of two parts: Compute and I/O. Compute, the internal state of the abstract computer, unites two different executions of computing. A Model, a stochastic process, and a Sandbox, a deterministic process. I/O, or the computer’s interaction with the outside world, also consists of two parts. Search, a vaguely defined concept, and Embeddings, representing an ontology, or a base of known facts.
He found it important to explain the model training process (pre-training, mid-training, and post-training), emphasizing the importance of training has shifted from pre-training to mid- and post-training. He put this in context by invoking the Jagged Frontier, a measure of a model’s generality, specifically its performance at a range of professional tasks (coding, creative writing, law, etc.). Usage data at Perplexity shows different models are suited to different tasks due to the architecture of their mid-training and post-training pipelines, and what “they emphasize”.
He finished with an exploration of the AI Stack. In some ways, it’s a measure of the intellectual property of a software product. Two years ago in 2024, the model was the largest part of the stack, the largest source of IP. Now, interfaces are becoming larger parts of the stack. People need to be able to use AI. What is intelligence without action?
I was able to ask a few questions:
Q: What is the future of systems software research?
- rolling back state changes in OS/system
- sandboxing not just a single container/vm, but a distributed system.
Q: How do they perform evaluations?
- they look at usage metrics of their users, they have a lot of data.
- If and when a user switches models is an important signal.
- In-house model evaluations are too much manual labor, and get out of date.
Q: Intellectual Property for AI generated work?
Very contested, he can’t speak to it, said to “ask perplexity” for the latest developments in this space.
Fascinating breath of fresh air flown in from California. Some points he made lend themselves well to our endeavor.
- emphasis on interfaces is growing, intelligence is not end-all be-all.
- usage data from students is valuable for evauating model capabilities.
- perplexity thinks the future of AI reasoning / on-line learning is developing a “ontology” or “knowledge base”. Sounds like a class textbook.
- frontier models are being caught up by open-source models. We can run great models on RCAC, and keep student data secure.