Week 5
4,827 words · 25 min read
Summary
February 9 - February 15
Meetings
- 2/10 3:30-5PM Tuesday, 1-on-1-on-1 with Prof. Adams and Grace Lingley
- 2/13 1:30-2:30PM Friday, Instructional Team Meeting
Accomplishments
- Cloud Assignment 2 Part 1 released on Tuesday
- Cloud Assignment 2 Part 2 released on Friday
- 100+ student submission attempts for Cloud Assignment 2 by Friday
- 200+ student submission attempts for Cloud Assignment 2 by Sunday
Cloud Assignment 3
Motivation: The detection history feature went viral. Funny bird photos captured with your application are all over BipBop and CrackerGraham. It proved to investors you’ve gained traction and found PMF. You just raised a Series-A round of $30 million dollars. Time to scale.
Ethical concerns: Investors are demanding that they find new sources of revenue. One is also on the board of a large financial company interested in purchasing your user data to feed into credit models they use to set interest rates for clients who love squirrels.
Part 1 of Cloud Assignment 3 will focus on implementing the N-tier system architecture for Software-as-a-Service applications. Part 2 will focus on implementing an application feature that introduces the idea of distributed systems. This system/application split will continue through assignments. This format inspires many new assignments. If we take up our previous conversation of different “tracks” in the Cloud Computing course, for one or two assignments, students could select from a set of Cloud Assignments, each with a different focus: “Network Engineer”, “Data Engineer”, “AI/ML”, “Full-stack Developer”, “Cybersecurity”, “High-performance Computing”, “Computational Biology”, “Simulation and Modeling”, “Site Reliability Engineering”. Each assignment introduces a system architecture in Part 1, and then solves a relevant problem using it in Part 2.
Part 1: N-Tier Architecture
- verify CA2 resources have been cleaned up
- introducing docker compose using nginx
- initialize EC2 instance using Ansible
- introducing container image repository
- deploy reverse proxy on EC2 using Ansible (on c7i-flex.large)
- register a domain name (DNS A record)
- introduce terraform and import CA3 architecture, add CA2 architecture back
- make bird.ai django application production-ready
- minimize docker image size by optimizing system and application dependencies
- deploy bird.ai application behind reverse proxy (on t3.small or t4g.small)
- create a postgreSQL server and connect to the bird.ai application (on m7i-flex.large)
Part 2: Squirrel-due University
- implement squirrel detection
- introduce large file S3 uploads,for mobile photos.
- implement EXIF data stripping and IP address collection
- host MaxMind GeoLite server for Geo-IP.
- host OpenStreetMap instance with Greater Lafayette map files.
- map will show location, bird picture, time taken.
- implement REST API for gossip protocol, peer IPs distributed by instructor server (which is managing DNS).
I will have to host an assignment server, with two REST endpoints, acting as a centralized co-ordination server to power the gossip protocol implementation
George, I’d like to have a guest blog or video on the topic of software ethics in the context of this assignment, can you recommend anyone?
Grace, I’d like you to write a “The More You Know” for Cloud Assignment 3. We have students updating the application code of the YOLO convolution neural-network model to detect “squirrel” as well as “bird”. You’ve worked with CNNs before, would you like to write a description of the specific YOLO model we are using, and provide specifics about how our natural language classification is transformed into an image classification?
The assignment is in progress.
Cloud Assignment 4
Motivation: Series B-*
Orchestration + Kubernetes
There could be an interesting ML element to add to for this one. Maybe they distill a LLM in RCAC then take the model weights and deploy it to a Kubernetes cluster using an ML runtime like Ollama.
The students will handle DNS Delegation use CoreDNS, the DNS that Kubernetes itself uses. I will delegate a subdomain matching their student account name to them, and they’ll configure CoreDNS for DNS delegation. I will also have to figure out some way to handle the SSL certificates for the cluster.
It would be nice if I could collaborate with other students, professors, or computing professionals at Purdue for this assignment, I don’t have practical experience with Kubernetes and I’m sure someone on Purdue’s campus does. Does RCAC run any Kubernetes clusters? They have an Anvil slide deck that mentions Kubernetes clusters there: https://www.rcac.purdue.edu/training/anvilcomposable. It’s basically a training document, so I’ll use it as reference material for the assignment.
I’d also like to meet someone who has trained LLMs before. I’d like their opinion and perspective on training and deploying an LLM model as part of an assignment.
Cloud Assignment 5
Motivation: IPO or Acquisition (Exit)
They will build their own FaaS. They will write their own Terraform provider (using Go!) that will deploy an application onto that FaaS. That application will be vibe coded by the student. The autograder will test that their FaaS works and that their terraform provider for it works, but the student will have to bring their vibe coded application deployed on their own infrastructure into class to show it off to the instructional staff and their peers to get the rest of their points.
Crazy Idea
My Cloud Assignments could be “written” by AI, like Claude Code. It’s already a conversational stream of markdown text, peppered with <components> and begging to be interactive. A cloud assignment could be truly very interactive.
AI-controlled UI components: I have “The More You Know”, “Hint”, “Vibe Check”. interspersing the assignment content. An “AI” bot is already involved in the course. It even assigns points! Talk about feedback! This goes beyond mastery learning, students could ask questions straight to the assignment, and the assignment would answer back.
It would be like a “A Young Lady’s Illustrated Primer” but for computer science education. An assignment would be a document published by the instructional staff, introducing and motivating the assignment. The student would then talk to the assignment to figure out what to do, driving the experience. The AI would guide them through the assignment, and add or subtract points along the way as they complete various tasks, until DING!DING!DING!DING! 100 points!
We would record every conversation a student has with the assignment, and pull a bunch of data about how they are learning and how we could improve. For example, with conversation content and telemetry, we would know precisely how much time a student spends on an assignment. I believe this is the holy grail metric of teaching. Studying the amount of time students spend on assignments gives incredible feedback as to the courses students are engaged with. Of course, different students will be engaged with different courses, interests vary. But I believe examining the variability of time spent on assignments by students would provide some very interesting patterns of behavior that would help improve assignment development and scheduling.
If the assignments continue in my style, they would be cute and fun. I could keep writing fun assignments like this, and they would become part of training data, so that the interactivity becomes better and more creative over time. If this is expanded to other classes, the components would be themed and appear differently according to the tastes of the instructor or the intended audience.
For example, my “<Info>” component appears as “The More You Know” callout in cloud assignments. It could appear as “Dive Deeper” in another course and be styled differently, even though the underlying component and intent is the same. This idea unifies the intent of different sections in an assignment across courses, while preserving a distinct identity for each course. A course could choose to disable certain types of components for their assignments if they don’t think it fits the content. For example, a competitive programming course would enable a leet-code style challenge component, while an intro programming class would disable it, but both would have “<Info>” enabled.
We could anonymize and examine individual learning outcomes by looking at the chat conversations. Both writing and voice would be possible. The student would speak, and have to read the response (no voice back, we don’t want to have to choose an accent for an AI voice, plus students should be encouraged to read).
I’ve already noticed during CS351 lectures, a majority of students have the course slides out and open on their computer. Most are ready to engage with course content that has been distributed to them over the internet. Also, students ask for practice exams, expressing a desire to practice curated content outside of class to prepare for an exam. A minority of students play games during parts of the lecture. If we could create interactive, curated, gamified assignments, students could practice on their own time in a fun and interesting way, and instructors would gain useful engagement data that would help improve their course (a flywheel).
Now, on the instructor’s side, it’s actually the same but flipped. The students will have a AI bot that guides them through completing an assignment. The instructors will have an AI bot that helps them write an assignment. This is an important part of the process. The student experience will only be as good as the assignments the instructors can write. Exceptional source material will deliver an exceptional educational experience. By giving an instructor tools that help them write the best assignment they’ve ever written, we’re giving an opportunity for a professor to amaze students, motivating them to take initiative and collaborate. The bot could also help the instructors manage the course. I still remember taking CS408 Software Testing with Pedro Fonseca. The assignments were exceptional in that course, I spent a lot of time on them and learned so much.
The instructor would create a new assignment and write out the learning outcomes. They would define a series of tasks they want the student to complete, and each task would have an associated test that could verify it was completed correctly. They would then write short essays on topics and ideas in the assignment, and add links to resources. This would be organized as a knowledge graph rather than a written document. The AI would then arrange and orchestrate the assignment, guiding students through the tasks according to the learning outcomes, and including content from the assignment knowledge graph along the way.
We could share the software with other universities and collect collaborators. We would share assignment content, increasing the base of high-quality training data for the AI. We would also share anonymized and processed conversation data, for analysis and training.
The AI Assignment would also hyperlink to high-quality course materials, whether that is news links, class slides (which are often open by half the class while in lecture), videos, or textbook chapters. When the AI creates a hyperlink we would archive the target’s content at the time so whatever was linked to and viewed in an assignment could be faithfully and accurately reproduced.
Research Direction:
- cloud computing services and infrastructure
- financial planning for cloud software
- conversational and interactive AI interfaces
- software testing for computer science pedagogy
- knowledge graph approach to curriculum development
- statistical methods for measuring student engagment
Preliminary data on student submissions
We had two students submit the day part 1 of the assignment was released.
The first student to finish part 1 of the assignment was ██████████████████, just a few hours after the assignment was released. He asked a question on Ed at 9:40PM, and his first submission was at 10:02PM. Their last submission was at 10:23PM, they were likely working on this assignment for just under an hour. He made 7 total submissions over 20 minutes.
The first student to submit was █████████████████, 4 hours after the assignment was announced. He posted on Ed when he couldn’t find the assignment on Gradescope. He made the first submission 1 minute after I activated it.
A metric to track is estimated time spent on assignment. We would define a “session” as a series of attempts where each sebsequent submission attempt is within an hour of each other. We could average number of sessions spent on the assignment, and then calculate the time per session by measure the time between the first submission and the last submission, then calculate the total time spent on an assignment by adding up all the session times. This could be visualized per-student, and as a class average and standard deviation.
A student submitted 5 times in a row with the same result. She made a post on Ed and it turns out she had a validation error in her choice of external ID (The autograder has been updated to have informative error messages for both the edge cases she triggered). Another metric to track will be number of sequent submissions with the same grading result. That would be a pro-active indicator that something is wrong with the assignment. She later completed Part 1 of the assignment after 16 submissions over 3 “sessions”, taking an estimated 4 hours.
Apart from Gradescope submissions, there are two other sources of student engagement. The first is the class Ed discussion board. When a student posts about an issue they are having with the assignment, we can be sure they are engaging with it. The second is Brightspace. It records the first time students view the Cloud Assignment HTML file. Using these three metrics, we’re able to build a larger picture of student engagement, from their first look at an assignment to their final submission.
Reflection on finishing Cloud Assignment 2
Cloud Assignment 2 has been a lot of work. I haven’t gotten enough sleep this week, and the effort has de-prioritized work for other classes. I’m happy with how the assignment has turned out, and I believe the trade-off I made this week was a good one. I am having a lot of fun! It’s bringing me back to new product launches I’ve been a part of.
This is part of the growing pains of delivering new curriculum content, and just like riding a bike, sometimes you need to pedal hard to get up to speed before you can cruise. I’m almost to a point where I can maintain a cruising velocity, let’s consider what I could build that would help me, and what I have already built during cloud assignment 2, that helps me deliver course content.
- tightening autograder test loops: already implemented, but would have to be improved for the course handover.
- standardized methodology for building and testing a cloud assignment test container: currently ad-hoc for assignment 2.
- publishing to brightspace: manual, but the kinks have been worked out and I can build an assignment document and upload/update it in Brightspace in less than 2 minutes.
- End-to-end test runs through the assignment: it’s just me and the early adopters at the moment. It makes sense, this assignment has a been a crunch.
- staging environment: incremental updates during a assignment period are dangerous. The method for handling bug fixes, or part 2 releases, is haphazard at the moment. Some kind of staging environment, or even end-to-end automated tests, would build confidence.
- versioning: At the moment, it’s not explicit what version of the autograder is running during a submission. If I versioned the test script, either by tying it to a git hash, or creating a content hash of the python file, I could both log it during the run so version/release information can be viewed in the gradescope UI by instructors, and I could also make it part of the submission back to the instructional site, so a student score is tied to the version of the autograder script that gave them that score.
Next assignment will go more smoothly, but perhaps we can keep the “Part 1” then “Part 2” release schedule. It lets us put out a cloud assignment early, and it encourages students to sit down and make time for two sessions of work on a cloud assignment, possibly increasing student engagement and learning outcomes. Students will have a first attempt, reflect on that attempt, and then approach the second part with a new perspective. It also lets us get early feedback on an assignment, the first day Ed posts of students engaging with the assignment release were helpful - “early adopter” feedback. For the curriculum developer, it places less pressure on delivering a whole assignment in a short time period by adding 2-3 days of slack for “Part 2”. Because our assignments have students complete them using a DevOps-oriented approach, returning to an assignment after a few days shouldn’t be an imposition because they’ll have built sufficient automation to get up and running quickly, and will have the autograder for instant feedback. I placed a <Notice> after Part 1 of the assignment is done that the student can stop their EC2 instance if they want to take a break without losing their work. Stopping the EC2 instance will save them money because they are not paying for idle CPU time. Because of the work we performed in Part 1, all they’ll need to start Part 2 is start their stopped instance and they’ll already have 50/100 points from the autograder and can get started on the rest of the assignment immediately.
Our Cloud Assignments are evolving to have two parts: the first has a system architectural focus, where students have to implement a canonical cloud architecture. The second is application focused, the students have to implement an application feature that takes advantage of, or demonstrates the capabilities of, that new system architecture. This highlights the feedback mechanism between product requirements and system capabilities, and provides insight into a common misunderstanding between product teams and engineering teams. For example, in our fictional bird.ai startup, the cloud assignment 2 conversation may have gone like: Product - “Hey, we’re just implementing a history page, how hard can that be?”, Engineering - “So we’re letting users upload and store as many images as they want? But at what cost?”. We could have early releases of the architectural parts of the assignment, then the application implementation part would be released a few days later.
It has taken me about 40 hours to complete this assignment, from writing the assignment text to developing the starter application and autograder test suite. I’d like to praise the programming language Python. Its ability to introspect its own structure has been exceptionally useful for developing an assignment that students can iteratively update and deploy in a DevOps-style. I’ve created a stub Django model students update throughout the assignment. The controller that uses that model to introspect on its structure to determine at what step the student is in the assignment, taking a different control path based on its guess. That way, students don’t have to update controller code to account for structural changes in the data model (like a professional software engineer would), they can focus on implementing the concept introduced in the assignment and then immediately see the effects of their implementation . If they’re curious, they can also then see how their implementation is being used by reading the controller file. The controller file is heavily commented, contrasting with the empty stub model file. Students will learn how the controller works by reading the code, and then have to use that knowledge to create a model based on just a few instructions and hints.
Something very useful during my time developing the assignment was having a solution application and starter application split. The solution application was the finished implementation of the whole project. I could iterate on that during the initial phase of writing the assignment in order to test out any ideas. The starter application is what the students will receive. It’s heavily commented, with indications where to perform the implementation for each assignment step. During testing, I could copy the starter into a new directory, iteratively apply updates taken from the solution application, and emulate the student experience. It showed me a lot: first, I realized I had disabled DEBUG mode in the Django applications, so error messages were obscured, which would have made debugging issues way harder for students. I also realized there were inconsistencies between the solution application I had been iterating on and the starter application, which I was able to fix. I will keep this application split for future assignments, it has worked out well.
A challenge during this assignment was managing disk space, both locally and on the remote server. Let’s identify the places where this crops up:
- Because of the
requirements.txtthat ships with the application, images end up being 2GB in size due to Python dependencies. - Because
docker runby default does not remove stopped container images, large images will accumulate and take up space. - Because they save the image they deploy to a .tar file, that is an additional 2GB of disk used.
- Students using Intel laptops are producing container images that are 8GB in size.
For the next assignment, I will have to optimize the size of the Python
dependencies. I will also have to instruct students on using the --rm option
with docker run and introduce them to the docker system prune command, to
clean up unused images. The systemd service definition I provided them handles
this on the server. I will avoid having students export tar files to disk by
having them push images to an ECR repository.
I’m not sure why Intel images are so large, when I did a multi-platform with a
linux/amd64 target and the image was 8GB. This is a concern because many
students in the class will be using Intel chips. I’m realizing I’ll have to
develop assignments to target both architectures. Although containers are
lightweight on a server, they’ve ended up being quite heavy on a laptop. A
possible way to remedy this would be to introduce a continuous integration
server (aka build server) server, where students send their build context
over, it builds it for them, and stores it in a class container repository.
Students would then pull from this image repository as needed, and we wouldn’t
have to worry about (1) if their PC architecture matches the cloud server (2)
if their PC is powerful enough to perform multi-platform container builds (3)
whether they have enough space on their laptop to deal with the detritus of
local container development.
A student was building containers for the platform linux/amd64 on their x86 architecture computer. When archived and sent to the t4g.small instance (ARM), the container would not run because Docker Engine does not come bundled with a virtual machine like Docker Desktop does for development.
Another aspect to this assignment is that a lot of compromises were made with security in order to simplify this assignment. We’re deploying a development-mode, permissive, somewhat “hackable” Django application onto the public internet. The risk is not high, there’s no privileged data, the instance has almost no privileges to other AWS services, the blast radius is small. How should we communicate this to students? That this is a learning exercise and to truly make the Django application production-ready would require a lot more detail work? I will address this in Cloud Assignment 3.
The instructional infrastructure has already been useful for helping debug student issues. A student posted on Ed about how they were stuck at 80/100 for the assignment. I was able to look at their last submission on the instructional site, grab their EC2 instance IP from the AWS snapshot taken of their account, and visit their web server to inspect the issue. This helped me quickly determine they had a permissions issue between Cloudfront and S3, and I was able to provide a timely and thorough response to them and encouraged them to make the post public so it would help other students. Having this information available has lowered the effort to debug student issues with assignments, allowing curriculum developers and teaching assistants to focus on the primary work of creating better course content, rather than become mired in chat-based debugging of a student issue.
Updates to instructional site
I’ve created graphs and summary tables on the instructional website to summarize assignment submission data. There are informational tooltips you can hover over to learn more about what data the charts display.
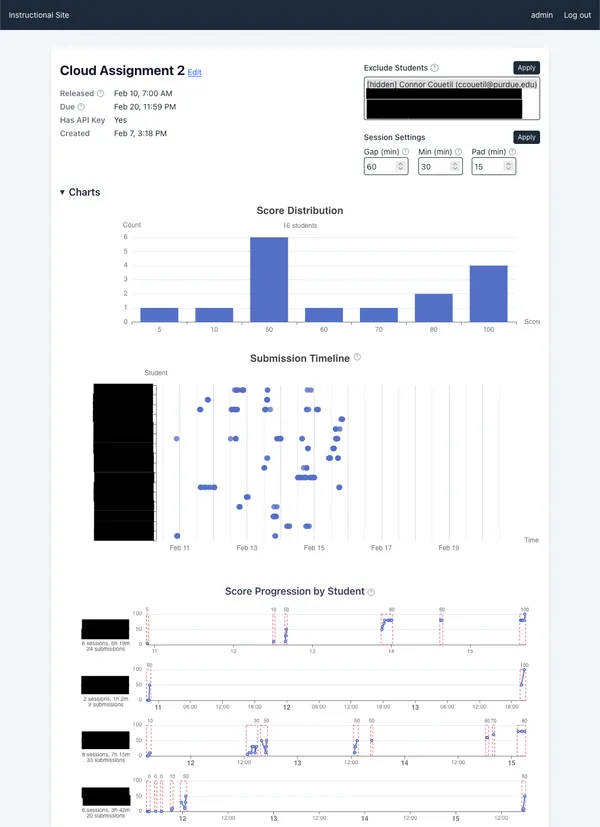
I will be collecting SSH session history and HTTP session history soon, and experiment with ways of displaying this history clearly to an instructor. There’s an opportunity to “auto-debug” using RCAC’s GenAI service.
The styles have been modernized, and an effort has been made to make it easily navigable. Please reach out with any feedback.
Paying the bills
I am spending money to help run the course. Let’s explore in what ways:
- host instructional infrastructure for data collection
- bring up infrastructure to test the cloud assignment
- using AI tools
- possibly buying a domain name for the course
I will have clearer accounting of the instructional infrastructure and cloud assignment testing costs at the end of the billing period, I will summarize it then. I have upgraded my Claude subscription to Max, $100/month, it will be sufficient as a coding agent for the rest of the semester, and I use Gemini at $20/month for research.
I will tag resources based on what their purpose to help keep track of spend, and every month do a end-of-billing period review.
Domain name for use with the course
I’d like a domain name managed by the instructional staff so students can learn about DNS and host websites behind human-readable names, they’ve been doing everything IP-based at the moment. I’m proposing CA3 and CA4 will introduce DNS to students in the form of A records first, then DNS delegation.
Let’s discuss possible domain names:
- boilers.cloud ($23/year @ Wordpress)
- purduecs.cloud ($23/year @ Wordpress)
- bird-ai.org ($12/year @ Wordpress)
- birdai.cloud ($23/year @ Wordpress)
- computing.cloud ($23/year @ Wordpress)
Jonathan suggested there is a possibility of running a class domain using Purdue’s infrastructure.
How I’ve been using AI
I use Claude Code for agentic coding. The new Opus 4.6 model released a month ago is a lot better at managing context length and working on multi-step long running tasks. It makes many fewer mistakes than 6 months ago, it’s a night and day difference.
One thing AI is good at is managing change. It is relentlessly detail-oriented,
and when I have to update one detail to satisfy some part of the assignment, it
will scan all other parts of the assignment for pieces that rely on that one
deatil. So if I have to make a quick update because a student identified a bug,
the AI will manage the change in that structure, and the correspondence between
assignment text and autograder script, much more quickly than I could myself,
or by using basic tools like grep.
Another thing AI is good at is driving automated testing loops. Because we have an autograder script, and I can create new infrastructure and deploy code onto it, the loop that builds the test script becomes very fast. I can test a bunch of scenarios by manually setting up the intended architecture, and the AI will write the autograder script that checks for and manages the differences between those scenarios. It makes me much more productive.
I do notice the AI makes mistakes, but they tend to be (1) conceptual, it doesn’t understand the purpose behind an assignment component, or (2) it makes different trade-offs when trying to solve problems, and chooses a different solution from the sphere of possibilities than the one I think is appropriate. To avoid these becoming systemic issues, I rely heavily on the “plan mode” with Claude Code. I’m able to fully review the plan document before any implementation starts, and I often go back and forth to resolve small details with it. Smaller changes are easy and quick to review, especially if I’m able to review a backlog of changes as it is moving ahead with the implementation. Using version control is important here, frequent commits improve confidence and let you backtrack easily. Integral is the practice of maintaining 100% line coverage in automated tests. It’s not a silver bullet, but it’s an effective “golden master” test, verifying code updates do not introduce regressions by verifying behavior has not changed, even if it hasn’t perfectly verified the behavior is correct.
Now for what I DON’T use AI for. All my writing, the text of the assignments, the weekly reports, is in my voice. For better or for worse! To make the cloud assignments interesting, fun, and engaging is a lot of work, and although I use AI for research (Gemini is great here), I don’t use it for writing.
Cloud Assignment 1 reflection
Ed Issues
11 issues, 3 remained private.
There were questions about requirements.txt. A student pointed out I had not
updated the due date in Brigtspace. Three students had issues running out of
temporary storage when installing Python dependencies on the server. A student
explained how to set the architecture type in order to find the instance needed
for the assignment. A student had a clarification question about installing
Python on the EC2 instance. A student could not connect to her instance, but
did not respond to inform me of the root cause. A student has two AWS
Accounts, and use different ones for CA0 and CA1, leading to some confusion.
███████████ posted about not being eligible for the free tier. And finally, an
hour before midnight, there was a 27 message back-and-forth debugging session
between a student and I to help him complete the assignment before the due
date, the root cause was a requirements.txt file that installed unnecessarily
large dependencies.
From looking at the lecture responses from students about CA1, I remember many
mentioned the parts of the assignment where they had to figure out some task
without explicit hand-holding, for example, many mentioned how figuring out
rsync was valuable. I will keep this in mind for future assignments, that
students like to figure things out on their own.