Week 6
2,384 words · 12 min read
Summary
February 16 - February 22
Meetings
- 2/17 3:30-5:00PM Tuesday, 1-on-1-on-1 with Prof. Adams and Grace Lingley
- 2/20 1:30-2:30PM Friday, Instructional Team Meeting
Accomplishments
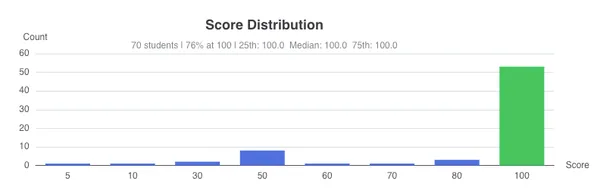
- Cloud Assignment 2 complete, 1200+ submissions, 76% of students scored 100.
- Instructional Site is now at https://www.cs351.cloud/
Cloud Assignment 2 Data
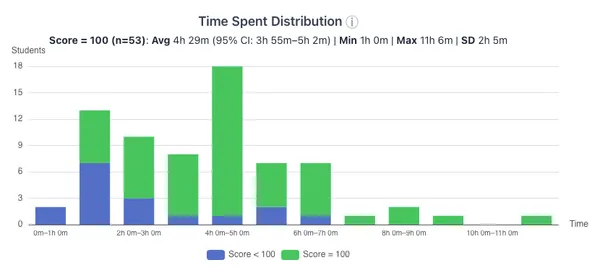
Cloud assignment 2 had an average 18 submissions and 4.5 hours spent per-student . I’m happy to report 76% of students achieved a 100%, and 94% received at least a 50%. 5 hours seems like a reasonable amount of time for an assignment that is due for 10 days, and it was likely exacerbated by container build times for several students.
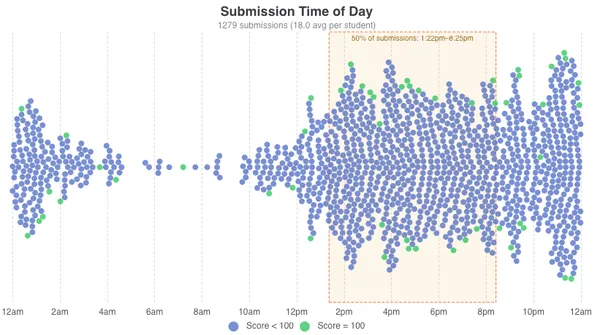
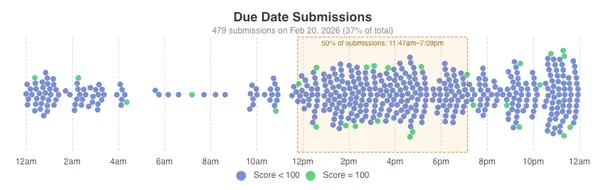
Submission times are clustered right after class, dropping a bit around dinner time, with the biggest spike between 10pm-midnight. There are very few submissions in the morning, students work on cloud assignments in the afternoon and at night. Over a third of submissions were made on the due date. Only a small percentage of students started the assignment on the last day, but 50% of students started working on the assignment only 3 days before it was due, and a majority of students only achieved a perfect score on the due date.
We now have a lot of data about student engagement for an assignment. When we write the Cloudbank proposal, we can use this data to produce a more accurate cost estimation of the course over the whole semester (they require us to provide a “Period of Performance (PoP) Cloud Spent management” table that projects month-by-month cloud spending for the research endeavor). This is also useful cost and engagement data we can bring to request more funding for the class. We’ll hold off on any specific projections until a couple more assignments are complete.
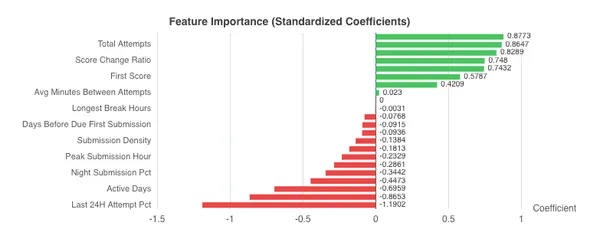
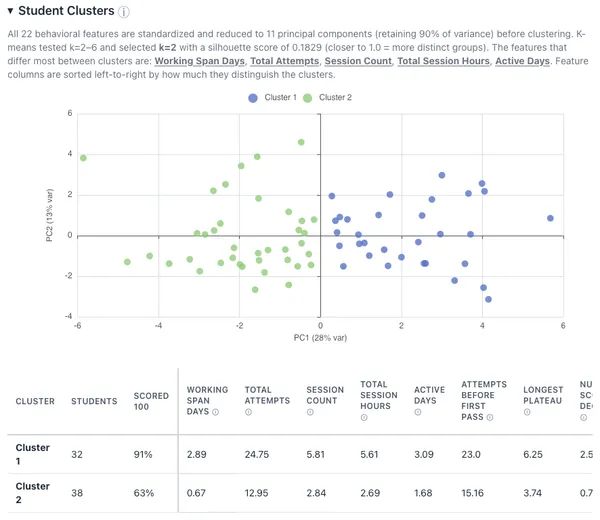
I did k-means clustering on a group of features and the students were best split into two cohorts. The most distinguishing features of these cohorts were (1) over how many days did they work on the assignment, (2) total number of attempts, (3) total number of sessions, (4) estimated time spent, (5) number of days actively working on an assignment. The logistic regression surfaced similar features, none are predictive though. We’re left with common sense: the more time and effort you put into the assignment, the better score you’ll get. Also, we shouldn’t build predictive models for cloud assignments, we’re not here to predict an outcome, but identify what students are struggling and push them all to the best outcome. Predictive analysis is limited in this domain, time is best spent observing descriptive statistics of student progress and effort.
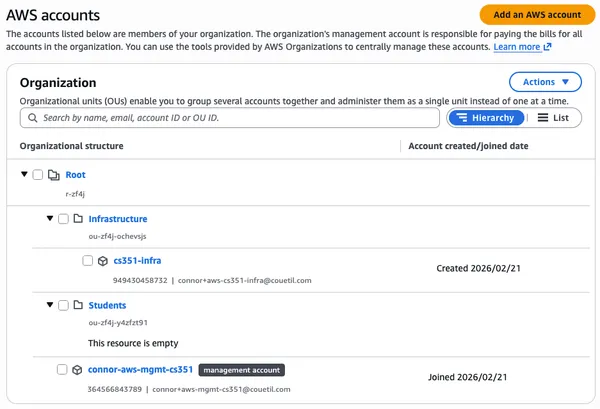
AWS Account Organization
I’ve overhauled how the instructional site is managed on AWS to anticipate:
- Course infrastructure handover to new staff.
- Cloudbank integration requiring infrastructure handover.
- Student account management requiring proper billing and permissions.
How the instructional site was intially set up has several downsides:
- Billing ambiguity - course costs are mixed with my personal use of AWS.
- Blast radius - misconfigured IAM policies or inappropriate resource use can escalate without limitation.
- No student isolation - difficult to impossible to properly restrict student account boundaries in the event of deeper course integration.
- Handoff friction - account handoff requires removing and shifting resources, causing operational burden and service downtime.
I’ve addressed these issues, and provided simpler solutions for the eventualities, by creating a dedicated AWS Organization for the CS351 project. Instructional infrastructure is isolated to a dedicated member account of the organization, and students may also be given their own personal member accounts, with all member accounts governed by Service Control Policies (SCPs), which provide greater guardrails than IAM policies.
Future maintainers can take over governance of the organization, or the member accounts can be transferred to another AWS organization under another institution’s control (Cloudbank, Purdue, RCAC). All resources in operation in the moved account at the time of the move will be unaffected. Student accounts may be created at the beginning of a semester, and deleted at the end, and will be governed according to different SCPs than the instructional infrastructure.
Billing is now isolated to each individual member account, making cost easy to measure. Resource use restrictions are easier to audit, and automation to this effect will be simpler to implement.
The instructional infrastructure permission model is simple to understand, it has full access to the capabilities of an AWS account. Let’s discuss a student account’s capabilities and characteristics.
A student’s AWS Account will be:
- Fully isolated - no cross-account access can occur, these safeguards are as strong as the ones between any normal users’ AWS accounts.
- Secure by default - we are able to enforce MFA and other security policies for any student account.
- Easy cost attribution - any billing activity within a student account is only attributable to that student.
- Easily torn down - student accounts will be defined in infrastructure-as-code, and can be created, modified and destroyed consistently and immediately (e.g. instant autograder configuration, updates for a new assignment).
- Assignment guardrails - Students will be granted resource access by assignment-specific SCPs limiting resource use to only what’s needed to complete the assignment.
Let’s discuss some of the initial guardrails, to paint a picture of what’s possible.
- Region lock - students can only use and create resources in “us-east-1”.
- IAM restrictions - students are limited to one IAM user provisioned for them by the instructional staff (for logging into the AWS console).
- Pre-approved Instance types - students may only use approved instance types in EC2.
I’ve hinted at ways to limit what services a student has access to, and how to limit their choices within a service, but I haven’t discussed how to limit the quantity of those services they’re able to consume. The practical approach is to have an AWS Budget alert at some threshold value ($20, $50, …), which when triggered causes an AWS Lambda function to apply a deny-all SCP to the account that surpassed the threshold. Instructional staff would also be alerted, and would have to get involved to determine what the student did to exhaust their resource quota, and what that means for their assignment grade.
We are now ready to (1) accurately track course infrastructure cost, (2) handover its management to any responsible party, (3) onboard Cloudbank as a funding source for cloud computing at Purdue, and (4) grant accounts to this semester’s student cohort and accept billing responsibility for future cloud assignments.
In order to organize a move to Purdue-controlled AWS accounts, from the instructor perspective, we would have to request a quota increase to the number of AWS accounts we’re allowed to make in an organization, the default is 10. From the student perspective, in-class we would show them how we use the cloud to help manage the course, and explain we are gathering data for a NSF proposal that will secure funding for the class, so we can do cool projects.
I suggest we bring this organization structure to the graduate section of the course. It may help them set up the infrastructure needed for their cloud project at the end of the semester.
graph TD subgraph Before["Before: Single Account"] A1[Personal AWS Account] A1 --- SP[Senior Project Website] A1 --- II[Instructional Infra] A1 --- SA[Student Resources<br/>shared namespace] end subgraph After["After: AWS Organization"] MGMT[Management Account<br/>org definition + billing] MGMT --> INFRA[Infra Account<br/>EC2, RDS, ECR, CloudFront] MGMT --> S1[Student Account 1] MGMT --> S2[Student Account 2] MGMT --> SN[Student Account N] PERSONAL[Personal Account<br/>senior project website<br/>unchanged] end Before --> After
Gradescope service interruption
Gradescope deployed an update on Thursday before the assignment was due that affected the test harness they deploy onto autograder instances. We hadn’t updated our container code for a few days, so the error did not originate from us. Gradescope’s test harness phones-home at each startup to download an updated script. Something in that update was not executing the grading script. I reached out to their help email that day. They were responsive, and the problem was fixed in about 6-8 hours. We were not the only group affected by the issue.
This provokes the question, can we operate the course when Gradescope is down? At the moment, no. However, we have a clear path forward in case we want to re-implement any features, it won’t be very difficult. The primary challenge is onboarding students to hold accounts on the instructional site. SSO through Purdue is likely out of the question, so the practical approach is “magic link” onboarding/login that is restricted to Purdue emails, and only those emails assigned to a class within the instructional site. Once students are onboarded, implementing autograding is easy.
If we want to run a “dual-stack”, that is, let students choose between submitting to Gradescope and the instructional site, that is also easy. The Gradescope container simply polls the instructional site for the autograding result, and when displaying the final score in the user interface, will link to a results page hosted on the instructional site.
We do need more error monitoring, I was only alerted to the issue because students on Ed brought it to my attention. Unfortunately, it’s a chicken-and-egg issue. We can’t log a failure if Gradescope doesn’t even run our code.
Ed Integration
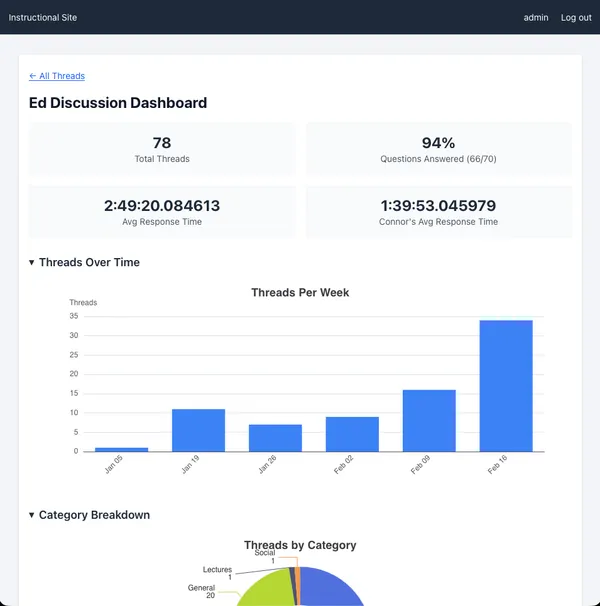
I’m syncing all activity in the Ed discussion board to the instructional site. I’ve cloned the discussion board, and created an activity summary dashboard.
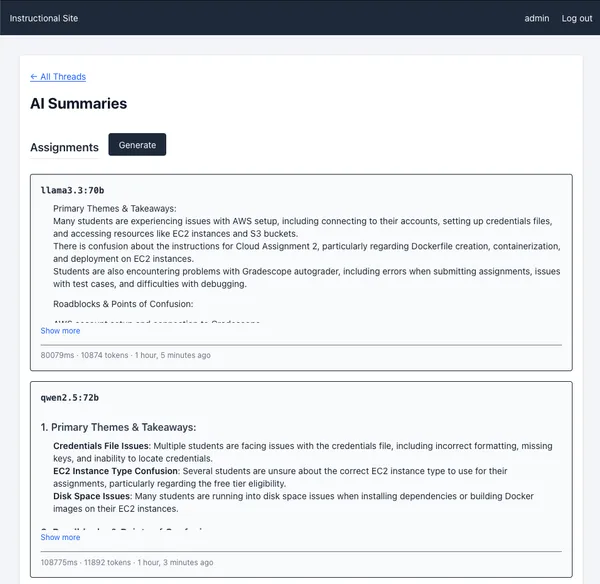
I’ve also integrated RCAC’s GenAI service and started experimenting with AI summaries of Ed categories.
I have a couple more experiments in mind.
- AI Ed Triage - answer student questions immediately using the mix of different data we have (class syllabus, cloud assignment text, student aws account snapshot, etc.).
- AI Real-time Assignment Debugging - If a student has an issue with a cloud assignment, have the AI run verification loops against the autograding script and “reference architecture” (a solution deployed in the instructional infrastructure).
Estimating the cost of instructional infrastructure.
So far, the instructional site has cost me ~$25. The new infrastructure will cost more, I’ve added
- Elastic IP: for rolling deploys of EC2 instances.
- Route 53: to manage DNS records for cs351.cloud.
- Wordpress Domain: cs351.cloud costs $24/year.
In order to audit these costs transparently, I’ve added an “Infrastructure Costs” section to the instructional site that uses the AWS Cost Explorer API and Cloudwatch “EstimatedBilling” statistic to display costs conveniently on-demand.
Instructional Site Downtime
I had downtime, due to pushing a feature out without an integration test between the autograder container and the instructional site. They were tested invidually, but not together. Compounded by accidentally rotating the assignment API token, which took me a moment to realize how to replace. The first domino that tumbled the rest was PostgreSQL rejected a raw file upload because it contained null characters, for which I had inadequate logging to realize quickly.
I’ve added rolling application deployments to the instructional site so data isn’t lost during deployments. The autograder containers have been updated to perform retries with exponential backoff when submitting student assignment results in order to accommodate blips in API availability during deploys.
I’ve also added rolling EC2 instance deployments by using the Elastic IP feature from AWS. Once I’ve confirmed a new instance is healthy after an AMI upgrade, or change in type/size, I can point the Elastic IP to it and remove the old instance. This is a two-step instance switchover primarily driven through Terraform and Ansible.
Our infrastructure is now more flexible, robust to both application and system upgrades, but could use more monitoring so we can be aware and pro-active when addressing performance issues and bugs.
Instructional Infrastructure improvements
Submission page load times grew to 10-20s, now at 500ms-1s. Our submission table was growing quadratically in size due to how much data Gradescope includes in the submission_metadata.json file. Our separated table is still growing quadratically in size, but it’s contained, and that problem is easy to address, the production database is 40MB on-disk out of 20GB available.
Remember, we’re still a t4g.small. It has 2 vCPU with burst, but that drops to .4 baseline vCPU. And 2GB of memory. The database is even smaller, a 1GB 1vCPU db.t3.micro, it accrues CPU credits at half the rate of the t4g.small. Both network and storage bandwidth are throttled. The application is pretty fast considering these limitations, burst scheduling fits it well.
Speedups:
- submissions list page
- assignment detail page
Solutions:
- optimized view queries, deferring large columns.
- split RAW and JSONB columns into separate tables
- denormalized submission fields computed from JSONB.
Total speedup: ~20x
In-class questions
I will be making an effort to record in-class questions and address them in Cloud Assignment content.
Content-delivery networks
Confusion about CDN vs data center networking. George drew a good distinction between
- Networking between VMs on same machine (Hypervisor-driven)
- Networking between servers on the same rack (Top-of-rack switch driven)
- Networking between racks in the same data center (Leafs and spines, east-west networks)
- Networking between data centers (Wide-area-networks, etc.)
- Networking between a user and their content (content may exist on a single computer. High-latency. So cache at the “edge”, where the edge is a lot of data centers all across the world optimized for caching and delivering content)
I will update Cloud Assignment 2, the final CDN section “Push it to the edge”, with a “<Info>” section that addresses some of these ideas.
Docker image naming
Confusion about Docker image names (id vs name vs tag). Will be addressed in Cloud Assignment 3
Cloud Assignment 2 Issues
Lots of student issues to work through this assignment, it was not a breeze. the code was good but not great, and lots of bugs slipped through. There were two primary problems:
Stuck at “push it to the edge”
Many students were stuck at 80 points, failing the last section, because the straightforward path through the assignment could cause caching issues. This part of the assignment I built when I was tired and working quickly, so its no surprise it is challenging to complete for students. This should have been a better experience for them, it was unnecessarily frustrating. Typically, obstacles in cloud computing are a learning experience, but I think this one went a little too far. It should be updated and refined for next semesters class.
Image Build Times
Took hours for many students. I counseled one student to build the image on the EC2 instance and it went much faster.
Part of the issue was I had students use Python 3.14.2, the most recent release, and a lot of packages didn’t have pre-compiled binaries available, so it default to compiling them during the build stage. A better Python version target would have been 3.12.
x86 images had a lot of GPU code. I could have given them better hints for how to compile a slimmer CPU-only image.
Cloud Assignment 4
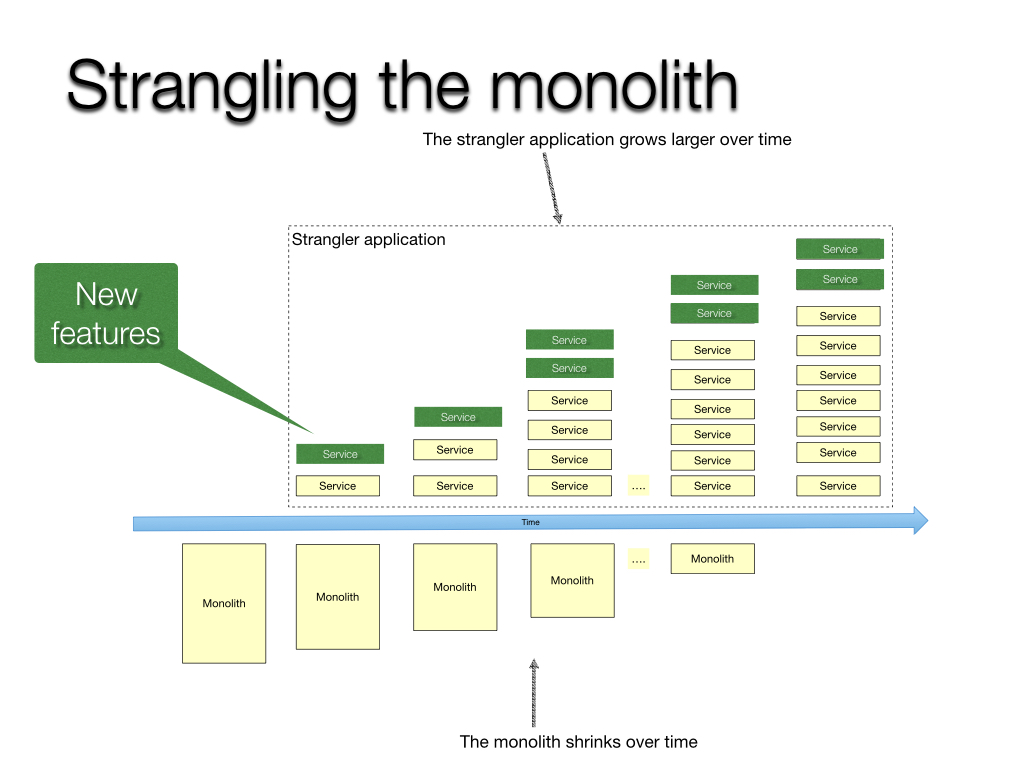
Technical Motivation: introduce microservices by taking the strangler fig approach, transition our N-tier web architecture to Kubernetes piece-by-piece. Helps “scale” parts of the service that have different reliability and load requirements.
Social Motivation: We have a big engineering team stepping on each others toes. Introduce Conway’s laws, and microservices, as a solution to this approach. (idea: should students work in teams? Gradescope allows group submissions). Different teams have different KPIs and perform different work (reliability vs agility, front-end vs back-end, etc.). How will you as a DevOps engineer make everyone productive?